Angular2のComponentライブラリ ng2-card を公開しました
Angular2の練習を兼ねて、ポートフォリオを書き換えていたのですがせっかくなので、↓のページのCard ViewのComponentをnpmに登録しました。 まだ結構雑な部分は残ってるのですが、とりあえず動くところまでできたのでAngular2のライブラリデビューです。
c-bata's portfolio | c-bata.link
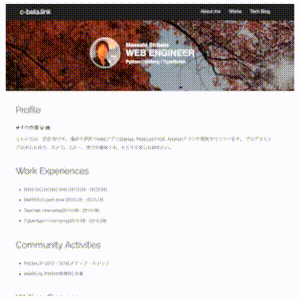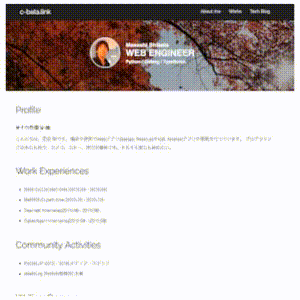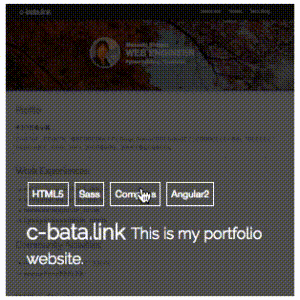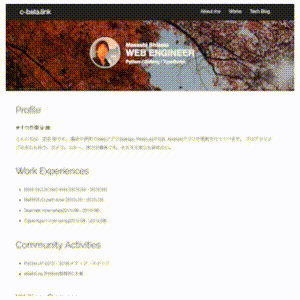
以下はメモ
Angular2の勉強
Angular2自体はTour of Heroesという公式チュートリアルから始めました。
- Tutorial: Tour of Heroes - ts
- npm i angular2してHello World!するところまで【改】 - Qiita
- [日本語訳] Angular 2 Component Styles
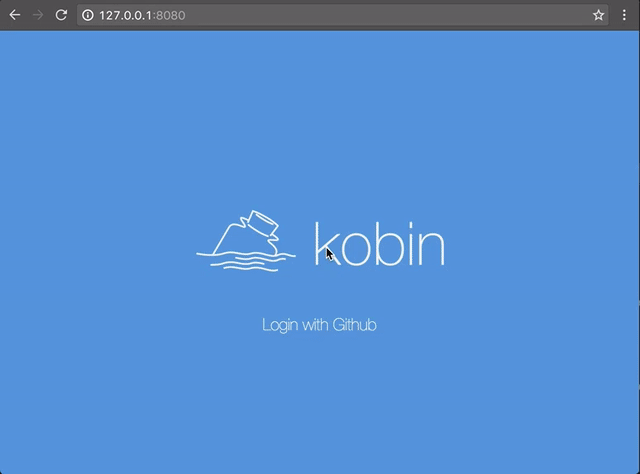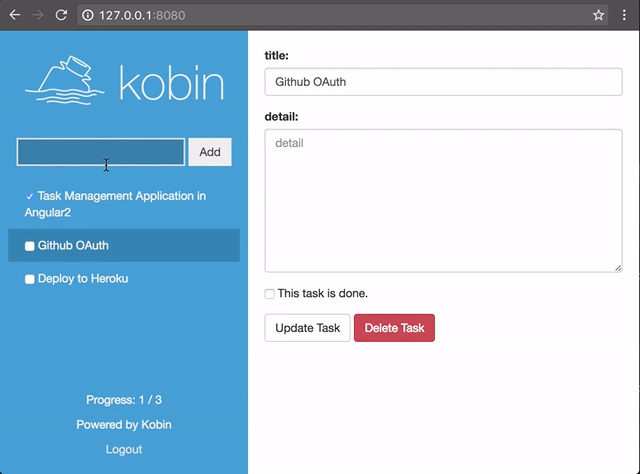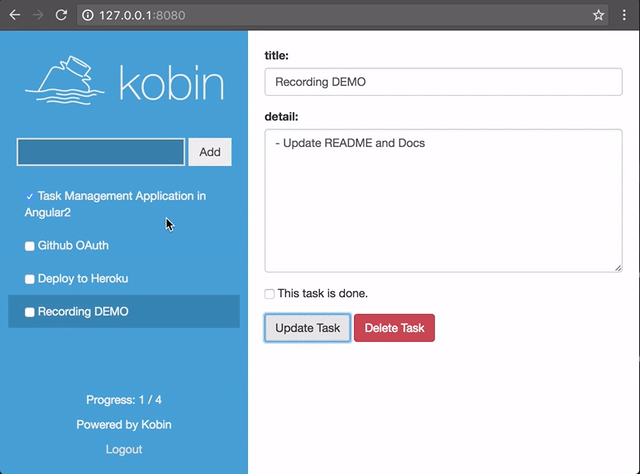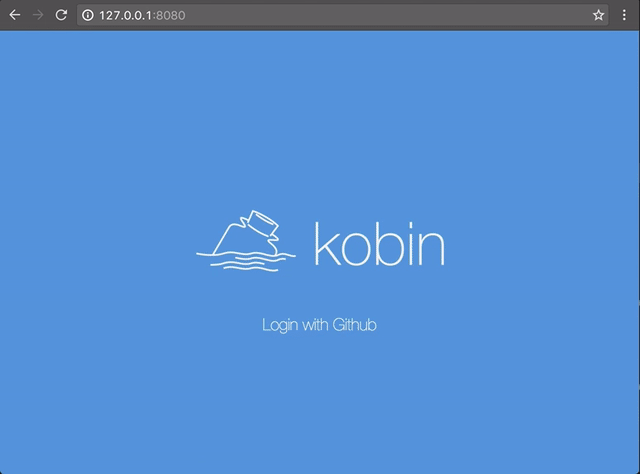
あとはKobinというPythonのWebフレームワークを作っているのですが、それのサンプルプロジェクトとしてAngular2を使ったTODOアプリを作ってみました。
- GitHub - c-bata/kobin-example: Example application using Kobin python web-framework.
- GitHub - c-bata/c-bata.github.io: This repository is my portfolio web site.
npmへの公開
npmへの公開はこちらを参考にしました。
- How to publish a library for Angular 2 on npm — Medium
- Angular2 用の npm パッケージを作成する (TypeScript) - Qiita
いくつかよく分からない挙動にぶつかったりしたのですが、まだRCだからということで納得しました。 何かエラーが出た時にどこからたどればいいのか分からなくいエラーメッセージが出ることも多かったので、自分にはまだ本番環境とかでの使用が難しそう。
使ったもの
- Angular2/TypeScript
- webpack
- tslint
また今度練習にReact.js版作ってみます
Flask 0.11で追加されたコマンドラインインタフェースを追ってみる
本日ついに、Flaskのnew versionがリリースされました。めでたいですね! 前回のリリースが2013/06/14だったので、ほぼ3年ぶりです。
バージョンを1.0に上げるという話がありマイルストーンも立っていましたが、0.11としてリリースされました。 1.0にしなかったのは、Flaskのコマンドラインインタフェースが特に大きな理由となっているようです。 この記事では、そのコマンドラインインタフェースを追ってみます。
Flask 0.11 Released | The Pallets Projects
Flask-Script
これまでdjangoのmanage.pyみたいなものが欲しい場合、Flask-Scriptというライブラリがよく使われていたと思います。
# http://flask-script.readthedocs.io/en/latest/ # manage.py from flask.ext.script import Manager from myapp import app manager = Manager(app) @manager.command def hello(): print "hello" if __name__ == "__main__": manager.run()
こんな感じのmanage.pyを作成すると、 manage.py runserver とか manage.py shell が使えます。
またFlask-MigrateというFlask-Scriptを利用したライブラリを使うことで、DBのマイグレーション等もDjangoライクに行うことができ、とても便利でした。
ちなみにFlask-Migrateの開発者のmiguelgrinbergさんは、Flask Web Developmentという書籍でも紹介しています(これとても良書でした)。
Flask Web Development: Developing Web Applications with Python
追記
Flask-Migrateは今回のFlaskのClickベースのCLIをサポートするのか聞いてみたところ、後方互換を保つように導入するのがやはり難しそうな感じ。FlaskのClickベースCLIのサポートはまだ時間がかかるかなぁという雰囲気
Flaskの新しいコマンドラインインターフェース
Added :command:flask and the flask.cli module to start the local debug server through the click CLI system. This is recommended over the old flask.run() method as it works faster and more reliable due to a different design and also replaces Flask-Script.
Flask開発者のmitsuhikoさんはclickというコマンドラインインタフェースを作成するための便利なライブラリを開発していました。 Flask-ScriptやFlask-Migrateは便利で広く使われていましたが、Flask-ScriptがClickを使わずに実装されています。 今回の変更はClickベースのCLIに統一したかったようです。早速0.11を入れてHelpを表示してみました
$ flask --help
Usage: flask [OPTIONS] COMMAND [ARGS]...
This shell command acts as general utility script for Flask applications.
It loads the application configured (either through the FLASK_APP
environment variable) and then provides commands either provided by the
application or Flask itself.
The most useful commands are the "run" and "shell" command.
Example usage:
$ export FLASK_APP=hello
$ export FLASK_DEBUG=1
$ flask run
Options:
--help Show this message and exit.
Commands:
run Runs a development server.
shell Runs a shell in the app context.
Run ServerとRun Shell
まずアプリケーションがFlaskのアプリケーションを見つけられるように環境変数 FLASK_APP でPythonのモジュールパスもしくはファイルパスを指定する必要があります。
サーバやシェルの起動は、最初からコマンドが用意されていて、↓のように行うことができます。
$ export FLASK_APP=hello $ flask run # Run Server $ flask shell # Run Shell
またデバッグモードで起動したい際も FLASK_DEBUG 環境変数で指定できます。いいですね。
CLIのカスタマイズ
ClickベースのCLIに統一されたため、自作のコマンドを追加することがClickに慣れている人は簡単に行えるようになりました。
import os import click from flask.cli import FlaskGroup def create_wiki_app(info): from yourwiki import create_app return create_app( config=os.environ.get('WIKI_CONFIG', 'wikiconfig.py')) @click.group(cls=FlaskGroup, create_app=create_wiki_app) def cli(): """This is a management script for the wiki application.""" if __name__ == '__main__': cli()
CLIプラグインの作成
プラグインを作りたい場合も↓のように、clickをベースのコードで記述出来ます。
import click @click.command() def cli(): """This is an example command."""
おわりに
とりあえず0.11のリリースおめでとうございます。 ClickベースのCLIに統一されるのは個人的にとてもうれしいですね。
他にもApplicationのFactory関数の扱いをどうすればいいかなど、ドキュメントの方に詳しく書かれているので、Flaskのプロジェクトを0.11アップグレードする際はこれを読みながらやると良いと思います。
http://flask.pocoo.org/docs/0.11/cli/

Flask Web Development: Developing Web Applications with Python
- 作者: Miguel Grinberg
- 出版社/メーカー: O'Reilly Media
- 発売日: 2018/03/25
- メディア: ペーパーバック
- この商品を含むブログ (1件) を見る
Feedy(Python)でRSSフィードをいい感じに処理する
最近、RSSフィードをfetchしてゴニョゴニョ処理したいと思うことが多かったのですが、特に気にいるライブラリが無かった *1 のでFeedyというライブラリを作ってみました。 個人的には結構気に入っていて、便利に使えているので紹介します。
もともと欲しかった機能・特徴としては、
- デコレータベースでシンプルに記述できる
- 当然、前回fetchした時間からの更新分のみの取得も可
- RSSフィードのリンク先のhtmlも自動で取得して、好きなHTMLパーサ(個人的にはBeautifulSoup4)でいい感じに処理したい
具体的には↓のように記述します
from feedy import Feedy feedy = Feedy('./feedy.dat') # 前回フェッチした時間とかを格納(Redisとかに自分で置き換えることも可能) @feedy.add('https://www.djangopackages.com/feeds/packages/latest/rss/') def djangopackages(info, body): # django packagesのRSSに載っている、パッケージ名と記事へのリンクを出力する例 print("- [%s](%s)" % info['article_title'], info['article_url']) if __name__ == '__main__': feedy.run()
他にも、全部は紹介しませんがプラスαの機能として
- デバッグ時とかは柔軟に実行時のオプションが指定できるCommand Line Interfaceも欲しい
- ページごとにFacebookとかはてブ数も気軽に取得できる仕組みがほしい
- ↑のような便利な機能を簡単に追加できる、プラグイン機構
- 上記のことを同期的に処理するとそれなりに時間がかかるので、裏側ではasyncioで高速に処理しておきたい(リクエストが飛び過ぎないようにsemaphoreも指定できる)
- HTMLをパースして文章をjanomeで形態素解析・各単語の出現頻度を数えた結果もほしい
Feedyを使ってみる
README頑張って書いたので、Feedyの基本的な使い方やCLIのオプションなどはGithubを見てください。 ここではとりあえずみなさんにも便利そうな使い方を3つぐらい紹介します。
記事のfacebookのいいね数、pocketの保存数、はてブ数を取得してみる
プラグインは自分で書くことも出来ますが、とりあえず僕の方で作った social_share_plugin を使ってみます。
SNSでのシェア数等が簡単に習得できます。
from feedy import Feedy from feedy_plugins import social_share_plugin feedy = Feedy('feedy.dat') feedy.install(social_share_plugin) @feedy.add('http://nwpct1.hatenablog.com/rss') def c_bata_web(info, body, social_count): print('=============================') print('Title:', info['title']) print('HatenaBookmark: ', social_count.get('hatebu_count')) print('Pocket:', social_count.get('pocket_count')) print('Facebook:', social_count.get('facebook_count'))
最新の記事3つ分ぐらい表示してみましょう
$ feedy example.py feedy -t c_bata_web -m 3 ============================= Title: Pythonを使ったデータ分析に関する内容をJupyter Notebookにまとめ始めました HatenaBookmark: 67 Pocket: 79 Facebook: 20 ============================= Title: Golangでつくる検索エンジン(Webクローラ、MongoDB、Kagome、gin) HatenaBookmark: 67 Pocket: 94 Facebook: 5 ============================= Title: Python製WebフレームワークのURL DispatcherとType Hintsの活用について HatenaBookmark: 41 Pocket: 66 Facebook: 1
成功 🎉
このブログの画像のURLを集めてみる
試しに↓のようにimgタグを全て表示してみます。
from feedy import Feedy from bs4 import BeautifulSoup feedy = Feedy('feedy.dat') @feedy.add('http://nwpct1.hatenablog.com/rss') def c_bata_web(info, body): soup = BeautifulSoup(body, "html.parser") for x in soup.find_all('img'): print(x)
実行すると↓の通り。
$ feedy example.py feedy -t c_bata_web -m 3 --ignore-fetched <img alt="この記事をはてなブックマークに追加" height="20" src="https://b.st-hatena.com/images/entry-button/button-only.gif" style="border: none;" width="20"/> <img alt="実践 機械学習システム" class="hatena-asin-detail-image" src="http://ecx.images-amazon.com/images/I/51%2BfZJOKEKL._SL160_.jpg" title="実践 機械学習システム"/> : <img alt="f:id:nwpct1:20160409180830p:plain" class="hatena-fotolife" itemprop="image" src="http://cdn-ak.f.st-hatena.com/images/fotolife/n/nwpct1/20160409/20160409180830.png" title="f:id:nwpct1:20160409180830p:plain"/> : :
はてなブックマークボタンなどノイズも混じっていますが、どうやら class="hatena-fotolife" は私がアップロードした画像のようです。
class="hatena-fotolife" で絞ってみます。
for x in soup.find_all('img', {'class': 'hatena-fotolife'}): print(x['src'])
実行してみましょう
$ feedy example.py feedy -t c_bata_web --ignore-fetched http://cdn-ak.f.st-hatena.com/images/fotolife/n/nwpct1/20160409/20160409180830.png http://cdn-ak.f.st-hatena.com/images/fotolife/n/nwpct1/20160107/20160107173222.png http://cdn-ak.f.st-hatena.com/images/fotolife/n/nwpct1/20160107/20160107173406.jpg :
成功 🎉
単語の出現頻度をカウントする
はてなブックマークのITカテゴリのホットエントリーやHacker Newsの一覧から自分の興味のある記事だけ抽出したいと考えています。 そのためには、Bag-of-Wordsした結果に対してTF-IDFの計算やクラスタリングやトピックモデルなどの機械学習手法を当てはめるとよさそうです。 全部説明するのは長いので、ここではBag-of-Wordsをするところまで紹介。
from feedy import Feedy from feedy_utils import word_counter feedy = Feedy('feedy.dat') @feedy.add('http://b.hatena.ne.jp/hotentry/it.rss') def hatena_it(info, body): print(word_counter.count_words(body).most_common(20)) # 出現回数の多い単語を20個取得して表示
実行してみます
$ feedy example.py feedy -t hatena_it -m 3 --ignore-fetched
[('エンジニア', 583), ('paiza', 203), ('スケジュール', 129), ('人', 124), ('コミュニケーション', 90), ('ユーザー', 77), ('仕様', 75), ('jp', 73), ('tag', 72), ('B', 66), ('learning', 64), ('項目', 64), ('img', 64), ('jmp', 64), 62), ('業務', 61), ('http', 59), ('IT', 58)]
[('月', 1059), ('ユーザー', 140), ('document', 138), ('ハリス', 75), ('企業', 69), ('Google', 65), ('IT', 65), ('write', 60), ('amp', 42), ('GIGAZINE', 40), ('Facebook', 37), ('心理', 35), ('手法', 30), ('ムービー', 30), ('if','都合', 27), ('社会', 26), ('自分', 25), ('店', 25)]
[('var', 334), ('id', 327), ('ITmedia', 319), ('i', 300), ('name', 253), ('if', 217), ('position', 192), ('adRequest', 192), ('著者', 170), ('document', 167), ('d', 150), ('b', 150), ('getElementById', 149), ('div', 144), ('s',42), ('return', 140), ('ISP', 138), ('span', 136), ('js', 120), ('IT', 120)]
成功 🎉 実際には、printするのではなくscikit-learnのCountVectorizerに入れてしまったり、MongoDB等に保存しておくという使い方になるかと思います。
終わりに
プラグイン等を除いた、メインの実装は200行ぐらいで済みました feedy.py 。 今回はasyncioやaiohttpで高速化を頑張ってみたのですが、それについてはまた後日記事にまとめようとおもいます。

- 作者: Ryan Mitchell,嶋田健志,黒川利明
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/03/18
- メディア: 大型本
- この商品を含むブログを見る