最近の登壇資料と出版予定の書籍、インタビュー記事
最近は勉強会での登壇や書籍の出版などアウトプットが色々重なりました (昨年は一度もプロポーザルを書かず登壇依頼もなかったので随分増えました)。 そのたびにツイートもしてきましたが、ほとんど流れてしまって少しもったいない気がしたのでブログにまとめておこうと思います。
登壇資料
PyData.Tokyo Meetup #23「サイバーエージェントにおけるMLOpsに関する取り組み」
運営の方からお声がけいただき、MLOpsについてお話させていただきました。あまりMLのコミュニティで登壇してこなかったのと、参加者が500人以上いて緊張していたので、資料も気合を入れて準備しました。
このあと #PyDataTokyo にてお話させていただく「サイバーエージェントにおけるMLOpsに関する取り組み」の発表資料はこちらになります。
— Masashi Shibata (@c_bata_) 2021年5月26日
他の資料や書籍であまり詳しい解説がない話題もいろいろ扱っていると思うので、ご興味ある方はぜひご参加ください。https://t.co/4eWuxpWHZD
登壇資料の中では過去一番拡散され、Twitterでの反応もよく久しぶりに満足のいく発表ができたかなと思います。動画も公開されているのでよければ見てみてください。
Optuna Meetup #1「CMA-ESサンプラーによるハイパーパラメータ最適化」
自分もコミッターを務めているハイパーパラメータ最適化フレームワーク「Optuna」の勉強会で、CMA-ESという最適化アルゴリズムの話をしてきました。 こちらも450人程度参加者が集まっていて、Optunaの人気の高さに驚きました。動画は公開されていません。スライド資料だけ読んでもよくわからないかもしれませんが、以前Optunaのブログで記事も書いているので興味のある方はこちら読んでみてください。
#Optuna Meetupの発表資料です。CMA-ES (Covariance Matrix Adaptation Evolution Strategy) の概要とOptunaでの利用方法について解説します。
— Masashi Shibata (@c_bata_) 2021年6月26日
また最適化アルゴリズムのバグを減らすために取り入れている継続的ベンチマークやFuzzingまわりの話も触れる予定です。https://t.co/AdGzrlLTDB
World Plone Day「Web パネルディスカッション(Python Webと非同期)」
Python製CMS「Plone」の国際カンファレンスであるWorld Plone Dayのパネルディスカッションで、寺田(@terapyon)さんにお声がけいただきパネラーをやってきました。 といってもPloneを使ったことがないので普通にPython Webフレームワークの非同期対応について話してきました。
一緒にパネルで話した @hirokiky さんや @aodagさんも含め全員がWSGIフレームワークを書いたりしたことがあるぐらいには、Webフレームワークの設計や実装を理解しているメンバーなのでやや踏み込んだ話が多かったと思います。 自分自身色々キャッチアップできてとても勉強になりました。個人的に印象に残った話だけメモしておくと:
- SQLAlchemyの非同期対応が最近入った。
- DBドライバーの非同期対応がなかなかまだ厳しいという話
動画はちょっと長いのですが、前半45分がPythonと非同期に関する話になります。
CA BASE NEXT「サイバーエージェントにおけるMLOpsに関する取り組み」
サイバーエージェントの若手世代による社外向け技術カンファレンスである『CA BASE NEXT』でも話してきました。内容はPyData Tokyoで話したものと同じですが、時間がこちらは30分しかなかったため、GeventやWebSocketまわりの話を削ってお話しています。
書籍
実践Django Pythonによる本格Webアプリケーション開発(翔泳社:7月19日発売)
PythonのWebフレームワーク「Django」の書籍です。今月19日発売になります。初の単著書ということもあり出版にあたって色々想いもあるのでこちらについてはまた発売日にブログを書こうと思います。

エキスパートPythonプログラミング改訂3版(KADOKAWA:7月30日発売)
エキスパートPythonプログラミングの改訂3版です。今月30日発売になります。内容がアップデートされただけでなく新しく追加された章もあるので改訂2版をお持ちの方もぜひ手にとってみてください。

インタビュー記事
今年3月に会社のFEATUReSというメディアから、2本のインタビュー記事が出ました。 昨年も個人インタビュー記事を書いていただけたのですが、こんなに何度も取り上げていただけることはあまりないので嬉しいです。
PythonとOSS開発とフレームワーク解析の日々はやがて世界5位の研究成果につながる FEATUReS
サイバーエージェント社内にはDeveloper Expertsという肩書きを持つエンジニアが8名在籍しています。自分は昨年からPython領域のDeveloper Expertsに任命されていて、そのときの就任インタビュー記事が今年3月に公開されました。
生み出したのは、世界レベルの実績。研究/OSS開発で切り開くハイパーパラメータ最適化の未来 - FEATUReS
現在所属しているハイパーパラメータ最適化チームのインタビュー記事です。現在は同期のリサーチャーである野村と2人で活動しているのですが、ここ1年は色々とまとまった成果が出てきました。研究者も開発者もいい人がいたらぜひ手伝っていただきたいなと思っているので、もしこの辺興味がある方いたらお声がけいただけると嬉しいです。

おわりに
ここ2-3ヶ月は、登壇資料ばかり書いていてメインタスクがおろそかになってしまった気がします。昨年いろいろ頑張って成果がでた貯金のおかげで、昨年末・今年の4月と全社表彰でベストエンジニア賞をいただけたりもしましたが、もう貯金も切れてしまったと思うのでここから挽回したいなと思います。
Pyppeteer(with headless Chromium) + GitHub Actionsでoptuna-dashboardの継続的E2Eテスト
以前 optuna-dashboard というWebツールを開発・公開しました。 もともと Goptuna のために実装したReact.js + TypeScript製のSPAのWebツールでしたが、Optunaでも使えるようにしたところ、周りでも使ってるよという声をいただくことが増えてきて、公式に利用が推奨されるようになりました。
Optuna v2.7.0 released, with new tutorials, examples, and code improvements! @c_bata_ has fully redesigned the dashboard. Try out the new version with `pip install optuna-dashboard` and then `optuna-dashboard $STORAGE_URL`!https://t.co/MynWjxFYBF pic.twitter.com/8mGCrXzu3N
— OptunaAutoML (@OptunaAutoML) 2021年4月5日
基本的に1人で雑に開発をしていたのですが、バグを出すといろんな方に迷惑をかけそうなので、もうすこしちゃんとテストまわりを整備することにしました。 Python (Bottle) 製のAPIサーバーのユニットテストはもともと結構ちゃんと書いていたのですが、問題はフロントエンドのコードのテストです。 自分がフロントエンドのテストテクニックに詳しくないというのもあるのですが、Plotly.jsによるグラフ描画が主な処理になるため、ユニットテストで保証できる振る舞いはそれほど多くありません。またグラフの描画に必要な情報もやや複雑で、OptunaのFrozenTrialという試行情報を各テストケースで用意するのは大変です。
そこで今回はPyppeteerを使ってVisual regression testingのようなアプローチ *1をとったのですが、結構便利でやってよかったなと思ったので記事に残しておきます。
Pyppeteerを使ってさまざまな目的関数に対するDashboardの表示を確認する
OptunaのFrozenTrialに相当する情報を手動で用意するのは面倒なので、実際にさまざまな目的関数をOptunaで評価して、その評価結果の入ったInMemoryStorageをもとにDashboardを起動、Pyppeteerでアクセスします。コードを簡略化するとざっくり↓のような感じです (全体のコードは こちら)。
import asyncio import threading import time import optuna import os from optuna_dashboard.app import create_app from pyppeteer import launch from typing import List, Tuple from wsgiref.simple_server import make_server host = "127.0.0.1" port = 8080 output_dir = "tmp" def create_optuna_storage() -> optuna.storages.InMemoryStorage: storage = optuna.storages.InMemoryStorage() # Single-objective study study = optuna.create_study(study_name="single-objective", storage=storage) def objective_single(trial: optuna.Trial) -> float: x1 = trial.suggest_float("x1", 0, 10) x2 = trial.suggest_float("x2", 0, 10) return (x1 - 2) ** 2 + (x2 - 5) ** 2 study.optimize(objective_single, n_trials=100) # Pruning with no intermediate values study = optuna.create_study( study_name="binh-korn-function-with-constraints", storage=storage ) def objective_prune_with_no_trials(trial: optuna.Trial) -> float: x = trial.suggest_float("x", -15, 30) y = trial.suggest_float("y", -15, 30) v = x ** 2 + y ** 2 if v > 100: raise optuna.TrialPruned() return v study.optimize(objective_prune_with_no_trials, n_trials=100) # No trials optuna.create_study(study_name="no trials", storage=storage) return storage async def take_screenshots(study_ids: List[int]) -> None: browser = await launch() page = await browser.newPage() await page.setViewport({"width": 1200, "height": 3000}) for study_id in study_ids: await page.goto(f"http://{host}:{port}/dashboard/studies/{study_id}") time.sleep(5) await page.screenshot( {"path": os.path.join(output_dir, f"study-{study_id}.png")} ) await browser.close() def main() -> None: os.makedirs(output_dir, exist_ok=True) storage = create_optuna_storage() app = create_app(storage) httpd = make_server(host, port, app) thread = threading.Thread(target=httpd.serve_forever) thread.start() study_ids = [s._study_id for s in storage.get_all_study_summaries()] loop = asyncio.get_event_loop() loop.run_until_complete(take_screenshots(study_ids)) httpd.shutdown() httpd.server_close() thread.join() if __name__ == "__main__": main()
このプログラムの流れは次のような感じです。
- Optunaで実際にOptunaで様々な目的関数の最適化を回す (
create_optuna_storage()関数)。 - InMemoryStorageを使ってoptuna-dashboardのAPIサーバーを別スレッドで立ち上げ
- Pyppeteerを使ってheadless Chromiumで各ページにアクセスして、スクリーンショットを撮影
- Pyppeteerの処理が一通り終われば、WSGIRefのサーバーを終了
実際にOptunaで最適化を回し、そのStorage情報を使ってJSON APIサーバーを立ち上げているので、FrozenTrialのfixtureを手動で頑張って用意する必要はありません。実行すると↓の画像のようにスクリーンショットが生成されるため、様々な目的関数に対する表示結果を簡単に確認できるようになりました。
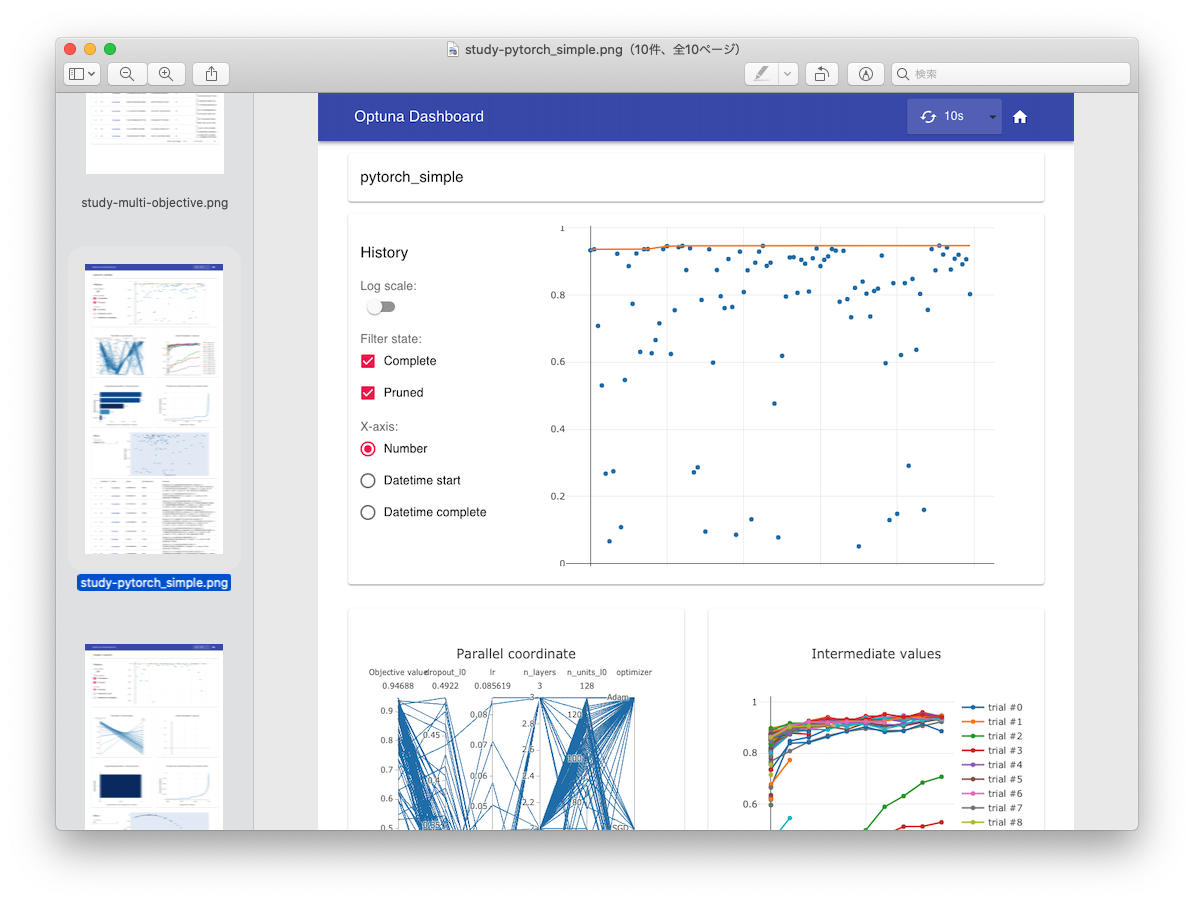
実際結構便利で、表示中にクラッシュしていたりすると真っ白のスクリーンショットが生成されるのですぐに気が付きますし、質的変数とかの表示がちゃんとできてるかみたいなユニットテストでの確認が難しい問題も手軽に目視で確認できます。
GitHub Actionsで動かす。
せっかくなのでGitHub Actionsで動かしてみます。 撮影したスクリーンショットをGitHubのコメント欄に貼り付けるようにしようかと思ったのですが、結構いろんな目的関数で評価していることもあり画像の枚数が多く全部コメント欄に貼り付けるのはやや大変です。 将来的には画像をGIFとかにまとめて一気に見れるようにするのもいいかなと思いましたが、今回はもう少し簡易的なチェックのみを実行するようにします。
async def contains_study_name(page: Page, study_name: str) -> bool: h6_elements = await page.querySelectorAll("h6") for element in h6_elements: title = await page.evaluate("(element) => element.textContent", element) if title == study_name: return True return False async def take_screenshots(storage: optuna.storages.BaseStorage) -> List[str]: validation_errors: List[str] = [] browser = await launch() page = await browser.newPage() await page.setViewport({"width": args.width, "height": args.height}) study_ids = {s._study_id: s.study_name for s in storage.get_all_study_summaries()} for study_id, study_name in study_ids.items(): await page.goto(f"http://{args.host}:{args.port}/dashboard/studies/{study_id}") time.sleep(args.sleep) if not args.skip_screenshot: await page.screenshot( {"path": os.path.join(args.output_dir, f"study-{study_name}.png")} ) is_crashed = not await contains_study_name(page, study_name) if is_crashed: validation_errors.append( f"Page is crashed at study_name='{study_name}' (id={study_id})" ) await browser.close() return validation_errors
チェックしているのは、study_nameを含むh6タグが存在するかどうかです。 もしアプリケーションがクラッシュして真っ白になっていた場合、このチェックに引っかかるので最低限クラッシュしていないということはチェックできるようになりました。これをGitHub Actionsで動かします。
name: integration-tests on: pull_request: branches: - main paths: - '.github/workflows/integration-tests.yml' - '**.py' - '**.ts' - '**.tsx' - 'package.json' - 'package-lock.json' - 'tsconfig.json' jobs: test: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Node v14 uses: actions/setup-node@v2-beta with: node-version: '14' - run: npm install - run: npm run build:dev - name: Set up Python uses: actions/setup-python@v2 with: python-version: '3.x' architecture: x64 - name: Install dependencies run: | python -m pip install --progress-bar off --upgrade pip setuptools pip install --progress-bar off . pip install --progress-bar off pyppeteer - name: Cache headless chromium id: cache-chromium uses: actions/cache@v2 with: path: ./local-chromium key: chromium - run: pyppeteer-install if: steps.cache-chromium.outputs.cache-hit != 'true' env: PYPPETEER_HOME: ./local-chromium - run: python visual_regression_test.py --skip-screenshot --sleep 3 env: PYPPETEER_HOME: ./local-chromium
GitHub Actionsの設定はこんな感じで、思ったよりもスッキリかけました。特にハマりどころもなくスッと動きました。
- Nodeや依存ライブラリをインストールして、JSのコードをビルド
- Pythonや依存ライブラリをインストールして、optuna-dashboardを動かせるようにする。
actions/cacheを使ってheadless Chromiumのバイナリ (~150MB) をキャッシュ (PYPPETEER_HOME環境変数でキャッシュ先のディレクトリを変更できます)。- Visual regression testingを実行。スクリーンショットの撮影は必要ないので、スキップしています。またページ遷移してからchromiumの描画が完了するまで少し待つ必要があるので、各ページ3秒待ってからチェックを実行しています。
まとめ
Pyppeteerを使って手軽にVisual regression testが走らせられるようになり、動作確認がだいぶ楽になりました。 Google Summer of Codeのプロジェクトテーマになっていることもあり、先にこの辺を整備しておけてよかったかなと思います。 1つ気になるのはPyppeteerの開発が活発ではなさそうな点ですが、かなり便利なツールだったのでまた動かなくなることが増えてきたら自分も開発手伝いたいなと思います。
*1:開発のなかで見た目に変化が入ることは多いため、なにか画像のdiffをとるようなSnapshot testing的なことはやっていません。あまりこの辺の用語の厳密な定義がよくわからなかったので「のような」とぼかしました
mypyc_ipython: mypycを気軽に動かせるIPythonマジックコマンドの紹介と実装解説
最近mypyc(型ヒントのついたPythonのコードからC拡張を生成するコンパイラ)のコードを読んでいたのですが、Cythonの %%cython マジックコマンドみたいに手軽に確認したいなということでマジックコマンドを実装してみました。CythonやPythonとサクッと性能を比較したいときにぜひ使ってみてください。
ここでは実装時のメモと、mypyc・cython・(pure) pythonのマイクロベンチマークの結果を残しておきます。
実装について
IPythonマジックコマンドの実装自体は↓のページに書かれています。
Defining custom magics — IPython 7.25.0 documentation
ポイントとしては、 %loadext <module name> を呼び出したときに、そのモジュールに定義されている load_ipython_extension() 関数が呼び出されます。
そこに次のように関数を定義しておくと読み込まれます。
def load_ipython_extension(ip): """Load the extension in IPython via %load_ext mypyc_ipython.""" from ._magic import MypycMagics ip.register_magics(MypycMagics)
MypycMagics の実装のポイントとして、次のような手順でコンパイルから読み込みが実行されます。
%%mypycコードセルの中身をファイルに書き出す。- mypycが提供する
mypyc.build.mypycify(paths: List[str]) -> Extension関数を使ってsetuptoolsのExtensionオブジェクトを取得。C拡張のコードを生成・コンパイル。 - 生成された
.soモジュールを読み込む。- CythonだとPython2対応もあるため、
imp.load_dynamic()が使われていますが、 mypyc_ipython はPython3以降のみをサポートするため、importlibを使っています。 imp.load_dynamic()に相当する処理は こんな感じ で実装できます。
- CythonだとPython2対応もあるため、
- module内のattributesをすべて読み込み
- https://github.com/c-bata/mypyc_ipython/blob/cefc1ce28559194ea4de6d2f686385d84b0a970e/mypyc_ipython/_magic.py#L38-L50
- これまでgunicornなどに送ったpatch などで似たような処理を実装したことはあったのですが、
__all__をチェックするのを省いていたことに気づきました。たしかに見ない理由はあまりないので、今からgunicornの方にも修正patch送ってもいいかも。
あとは通常のPythonの関数と同じようにIPython上で実行できます。
マイクロベンチマーク
fibonacci数を計算するコードを2種類用意してみました。
再帰で実装
In [1]: %load_ext mypyc_ipython In [2]: %%mypyc ...: def my_fibonacci(n: int) -> int: ...: if n <= 2: ...: return 1 ...: else: ...: return my_fibonacci(n-1) + my_fibonacci(n-2) ...: In [3]: my_fibonacci(10) Out[3]: 55 In [4]: def py_fibonacci(n: int) -> int: ...: if n <= 2: ...: return 1 ...: else: ...: return py_fibonacci(n-1) + py_fibonacci(n-2) ...: In [5]: py_fibonacci(10) Out[5]: 55 In [6]: %load_ext cython In [7]: %%cython ...: cpdef int cy_fibonacci(int n): ...: if n <= 2: ...: return 1 ...: else: ...: return cy_fibonacci(n-1) + cy_fibonacci(n-2) ...: In [8]: cy_fibonacci(10) Out[8]: 55 In [9]: %timeit py_fibonacci(10) 10.3 µs ± 30.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) In [10]: %timeit my_fibonacci(10) 848 ns ± 5.82 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [11]: %timeit cy_fibonacci(10) 142 ns ± 1.18 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) In [12]:
今回のマイクロベンチマークではPureなPythonに比べ、mypycはおよそ1桁速くなっています。Cythonはさらに1/8の実行時間になりました。
(cythonのほうで int を使いましたが、Pythonのintとは意味が違うので、long long とかで比較するほうがよかったかもしれません。)
forループで実装
In [1]: %load_ext mypyc_ipython In [2]: %load_ext cython In [3]: %%mypyc ...: ...: def mypyc_fib(n: int) -> float: ...: i: int ...: a: float = 0.0 ...: b: float = 1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: In [4]: def py_fib(n: int) -> float: ...: i: int ...: a: float = 0.0 ...: b: float = 1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: In [5]: %%cython ...: cpdef cython_fib(int n): ...: cdef int i ...: cdef double a = 0.0, b=1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: ...: In [6]: timeit py_fib(10) 627 ns ± 3.81 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [7]: timeit mypyc_fib(10) 891 ns ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [8]: timeit cython_fib(10) 44.5 ns ± 0.092 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
mypycのコードはpure pythonよりも悪化しました。 Cythonは速いですね。ループ以下の処理がすべてPython APIを使わないコードに落ちている雰囲気があります。 ちなみにfloat(cythonではdouble)に変えたのは特に意味はありません。
まとめ
mypycの高速化はまだまだこれからだと思いますが、型ヒントのついたコードがとりあえずmypyc挟むだけで速くなるなら嬉しいですね。 実はmypyc互換で大幅に効率的なコードを生成するツールを今実装しているので、それも出来上がってきたらまたここで紹介したいなと思います。