Pyppeteer(with headless Chromium) + GitHub Actionsでoptuna-dashboardの継続的E2Eテスト
以前 optuna-dashboard というWebツールを開発・公開しました。 もともと Goptuna のために実装したReact.js + TypeScript製のSPAのWebツールでしたが、Optunaでも使えるようにしたところ、周りでも使ってるよという声をいただくことが増えてきて、公式に利用が推奨されるようになりました。
Optuna v2.7.0 released, with new tutorials, examples, and code improvements! @c_bata_ has fully redesigned the dashboard. Try out the new version with `pip install optuna-dashboard` and then `optuna-dashboard $STORAGE_URL`!https://t.co/MynWjxFYBF pic.twitter.com/8mGCrXzu3N
— OptunaAutoML (@OptunaAutoML) 2021年4月5日
基本的に1人で雑に開発をしていたのですが、バグを出すといろんな方に迷惑をかけそうなので、もうすこしちゃんとテストまわりを整備することにしました。 Python (Bottle) 製のAPIサーバーのユニットテストはもともと結構ちゃんと書いていたのですが、問題はフロントエンドのコードのテストです。 自分がフロントエンドのテストテクニックに詳しくないというのもあるのですが、Plotly.jsによるグラフ描画が主な処理になるため、ユニットテストで保証できる振る舞いはそれほど多くありません。またグラフの描画に必要な情報もやや複雑で、OptunaのFrozenTrialという試行情報を各テストケースで用意するのは大変です。
そこで今回はPyppeteerを使ってVisual regression testingのようなアプローチ *1をとったのですが、結構便利でやってよかったなと思ったので記事に残しておきます。
Pyppeteerを使ってさまざまな目的関数に対するDashboardの表示を確認する
OptunaのFrozenTrialに相当する情報を手動で用意するのは面倒なので、実際にさまざまな目的関数をOptunaで評価して、その評価結果の入ったInMemoryStorageをもとにDashboardを起動、Pyppeteerでアクセスします。コードを簡略化するとざっくり↓のような感じです (全体のコードは こちら)。
import asyncio import threading import time import optuna import os from optuna_dashboard.app import create_app from pyppeteer import launch from typing import List, Tuple from wsgiref.simple_server import make_server host = "127.0.0.1" port = 8080 output_dir = "tmp" def create_optuna_storage() -> optuna.storages.InMemoryStorage: storage = optuna.storages.InMemoryStorage() # Single-objective study study = optuna.create_study(study_name="single-objective", storage=storage) def objective_single(trial: optuna.Trial) -> float: x1 = trial.suggest_float("x1", 0, 10) x2 = trial.suggest_float("x2", 0, 10) return (x1 - 2) ** 2 + (x2 - 5) ** 2 study.optimize(objective_single, n_trials=100) # Pruning with no intermediate values study = optuna.create_study( study_name="binh-korn-function-with-constraints", storage=storage ) def objective_prune_with_no_trials(trial: optuna.Trial) -> float: x = trial.suggest_float("x", -15, 30) y = trial.suggest_float("y", -15, 30) v = x ** 2 + y ** 2 if v > 100: raise optuna.TrialPruned() return v study.optimize(objective_prune_with_no_trials, n_trials=100) # No trials optuna.create_study(study_name="no trials", storage=storage) return storage async def take_screenshots(study_ids: List[int]) -> None: browser = await launch() page = await browser.newPage() await page.setViewport({"width": 1200, "height": 3000}) for study_id in study_ids: await page.goto(f"http://{host}:{port}/dashboard/studies/{study_id}") time.sleep(5) await page.screenshot( {"path": os.path.join(output_dir, f"study-{study_id}.png")} ) await browser.close() def main() -> None: os.makedirs(output_dir, exist_ok=True) storage = create_optuna_storage() app = create_app(storage) httpd = make_server(host, port, app) thread = threading.Thread(target=httpd.serve_forever) thread.start() study_ids = [s._study_id for s in storage.get_all_study_summaries()] loop = asyncio.get_event_loop() loop.run_until_complete(take_screenshots(study_ids)) httpd.shutdown() httpd.server_close() thread.join() if __name__ == "__main__": main()
このプログラムの流れは次のような感じです。
- Optunaで実際にOptunaで様々な目的関数の最適化を回す (
create_optuna_storage()関数)。 - InMemoryStorageを使ってoptuna-dashboardのAPIサーバーを別スレッドで立ち上げ
- Pyppeteerを使ってheadless Chromiumで各ページにアクセスして、スクリーンショットを撮影
- Pyppeteerの処理が一通り終われば、WSGIRefのサーバーを終了
実際にOptunaで最適化を回し、そのStorage情報を使ってJSON APIサーバーを立ち上げているので、FrozenTrialのfixtureを手動で頑張って用意する必要はありません。実行すると↓の画像のようにスクリーンショットが生成されるため、様々な目的関数に対する表示結果を簡単に確認できるようになりました。
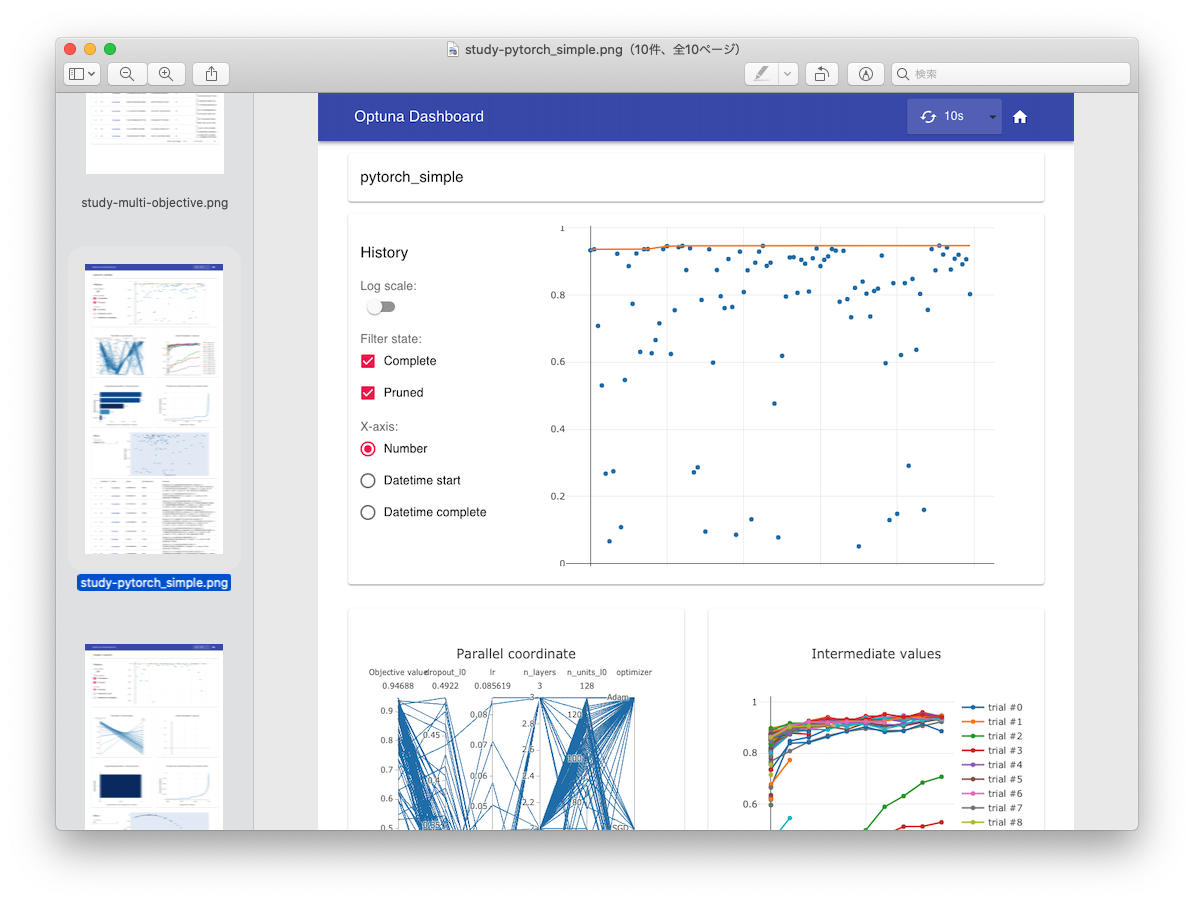
実際結構便利で、表示中にクラッシュしていたりすると真っ白のスクリーンショットが生成されるのですぐに気が付きますし、質的変数とかの表示がちゃんとできてるかみたいなユニットテストでの確認が難しい問題も手軽に目視で確認できます。
GitHub Actionsで動かす。
せっかくなのでGitHub Actionsで動かしてみます。 撮影したスクリーンショットをGitHubのコメント欄に貼り付けるようにしようかと思ったのですが、結構いろんな目的関数で評価していることもあり画像の枚数が多く全部コメント欄に貼り付けるのはやや大変です。 将来的には画像をGIFとかにまとめて一気に見れるようにするのもいいかなと思いましたが、今回はもう少し簡易的なチェックのみを実行するようにします。
async def contains_study_name(page: Page, study_name: str) -> bool: h6_elements = await page.querySelectorAll("h6") for element in h6_elements: title = await page.evaluate("(element) => element.textContent", element) if title == study_name: return True return False async def take_screenshots(storage: optuna.storages.BaseStorage) -> List[str]: validation_errors: List[str] = [] browser = await launch() page = await browser.newPage() await page.setViewport({"width": args.width, "height": args.height}) study_ids = {s._study_id: s.study_name for s in storage.get_all_study_summaries()} for study_id, study_name in study_ids.items(): await page.goto(f"http://{args.host}:{args.port}/dashboard/studies/{study_id}") time.sleep(args.sleep) if not args.skip_screenshot: await page.screenshot( {"path": os.path.join(args.output_dir, f"study-{study_name}.png")} ) is_crashed = not await contains_study_name(page, study_name) if is_crashed: validation_errors.append( f"Page is crashed at study_name='{study_name}' (id={study_id})" ) await browser.close() return validation_errors
チェックしているのは、study_nameを含むh6タグが存在するかどうかです。 もしアプリケーションがクラッシュして真っ白になっていた場合、このチェックに引っかかるので最低限クラッシュしていないということはチェックできるようになりました。これをGitHub Actionsで動かします。
name: integration-tests on: pull_request: branches: - main paths: - '.github/workflows/integration-tests.yml' - '**.py' - '**.ts' - '**.tsx' - 'package.json' - 'package-lock.json' - 'tsconfig.json' jobs: test: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Node v14 uses: actions/setup-node@v2-beta with: node-version: '14' - run: npm install - run: npm run build:dev - name: Set up Python uses: actions/setup-python@v2 with: python-version: '3.x' architecture: x64 - name: Install dependencies run: | python -m pip install --progress-bar off --upgrade pip setuptools pip install --progress-bar off . pip install --progress-bar off pyppeteer - name: Cache headless chromium id: cache-chromium uses: actions/cache@v2 with: path: ./local-chromium key: chromium - run: pyppeteer-install if: steps.cache-chromium.outputs.cache-hit != 'true' env: PYPPETEER_HOME: ./local-chromium - run: python visual_regression_test.py --skip-screenshot --sleep 3 env: PYPPETEER_HOME: ./local-chromium
GitHub Actionsの設定はこんな感じで、思ったよりもスッキリかけました。特にハマりどころもなくスッと動きました。
- Nodeや依存ライブラリをインストールして、JSのコードをビルド
- Pythonや依存ライブラリをインストールして、optuna-dashboardを動かせるようにする。
actions/cacheを使ってheadless Chromiumのバイナリ (~150MB) をキャッシュ (PYPPETEER_HOME環境変数でキャッシュ先のディレクトリを変更できます)。- Visual regression testingを実行。スクリーンショットの撮影は必要ないので、スキップしています。またページ遷移してからchromiumの描画が完了するまで少し待つ必要があるので、各ページ3秒待ってからチェックを実行しています。
まとめ
Pyppeteerを使って手軽にVisual regression testが走らせられるようになり、動作確認がだいぶ楽になりました。 Google Summer of Codeのプロジェクトテーマになっていることもあり、先にこの辺を整備しておけてよかったかなと思います。 1つ気になるのはPyppeteerの開発が活発ではなさそうな点ですが、かなり便利なツールだったのでまた動かなくなることが増えてきたら自分も開発手伝いたいなと思います。
*1:開発のなかで見た目に変化が入ることは多いため、なにか画像のdiffをとるようなSnapshot testing的なことはやっていません。あまりこの辺の用語の厳密な定義がよくわからなかったので「のような」とぼかしました
mypyc_ipython: mypycを気軽に動かせるIPythonマジックコマンドの紹介と実装解説
最近mypyc(型ヒントのついたPythonのコードからC拡張を生成するコンパイラ)のコードを読んでいたのですが、Cythonの %%cython マジックコマンドみたいに手軽に確認したいなということでマジックコマンドを実装してみました。CythonやPythonとサクッと性能を比較したいときにぜひ使ってみてください。
ここでは実装時のメモと、mypyc・cython・(pure) pythonのマイクロベンチマークの結果を残しておきます。
実装について
IPythonマジックコマンドの実装自体は↓のページに書かれています。
Defining custom magics — IPython 7.25.0 documentation
ポイントとしては、 %loadext <module name> を呼び出したときに、そのモジュールに定義されている load_ipython_extension() 関数が呼び出されます。
そこに次のように関数を定義しておくと読み込まれます。
def load_ipython_extension(ip): """Load the extension in IPython via %load_ext mypyc_ipython.""" from ._magic import MypycMagics ip.register_magics(MypycMagics)
MypycMagics の実装のポイントとして、次のような手順でコンパイルから読み込みが実行されます。
%%mypycコードセルの中身をファイルに書き出す。- mypycが提供する
mypyc.build.mypycify(paths: List[str]) -> Extension関数を使ってsetuptoolsのExtensionオブジェクトを取得。C拡張のコードを生成・コンパイル。 - 生成された
.soモジュールを読み込む。- CythonだとPython2対応もあるため、
imp.load_dynamic()が使われていますが、 mypyc_ipython はPython3以降のみをサポートするため、importlibを使っています。 imp.load_dynamic()に相当する処理は こんな感じ で実装できます。
- CythonだとPython2対応もあるため、
- module内のattributesをすべて読み込み
- https://github.com/c-bata/mypyc_ipython/blob/cefc1ce28559194ea4de6d2f686385d84b0a970e/mypyc_ipython/_magic.py#L38-L50
- これまでgunicornなどに送ったpatch などで似たような処理を実装したことはあったのですが、
__all__をチェックするのを省いていたことに気づきました。たしかに見ない理由はあまりないので、今からgunicornの方にも修正patch送ってもいいかも。
あとは通常のPythonの関数と同じようにIPython上で実行できます。
マイクロベンチマーク
fibonacci数を計算するコードを2種類用意してみました。
再帰で実装
In [1]: %load_ext mypyc_ipython In [2]: %%mypyc ...: def my_fibonacci(n: int) -> int: ...: if n <= 2: ...: return 1 ...: else: ...: return my_fibonacci(n-1) + my_fibonacci(n-2) ...: In [3]: my_fibonacci(10) Out[3]: 55 In [4]: def py_fibonacci(n: int) -> int: ...: if n <= 2: ...: return 1 ...: else: ...: return py_fibonacci(n-1) + py_fibonacci(n-2) ...: In [5]: py_fibonacci(10) Out[5]: 55 In [6]: %load_ext cython In [7]: %%cython ...: cpdef int cy_fibonacci(int n): ...: if n <= 2: ...: return 1 ...: else: ...: return cy_fibonacci(n-1) + cy_fibonacci(n-2) ...: In [8]: cy_fibonacci(10) Out[8]: 55 In [9]: %timeit py_fibonacci(10) 10.3 µs ± 30.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) In [10]: %timeit my_fibonacci(10) 848 ns ± 5.82 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [11]: %timeit cy_fibonacci(10) 142 ns ± 1.18 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) In [12]:
今回のマイクロベンチマークではPureなPythonに比べ、mypycはおよそ1桁速くなっています。Cythonはさらに1/8の実行時間になりました。
(cythonのほうで int を使いましたが、Pythonのintとは意味が違うので、long long とかで比較するほうがよかったかもしれません。)
forループで実装
In [1]: %load_ext mypyc_ipython In [2]: %load_ext cython In [3]: %%mypyc ...: ...: def mypyc_fib(n: int) -> float: ...: i: int ...: a: float = 0.0 ...: b: float = 1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: In [4]: def py_fib(n: int) -> float: ...: i: int ...: a: float = 0.0 ...: b: float = 1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: In [5]: %%cython ...: cpdef cython_fib(int n): ...: cdef int i ...: cdef double a = 0.0, b=1.0 ...: for i in range(n): ...: a, b = a + b, a ...: return a ...: ...: In [6]: timeit py_fib(10) 627 ns ± 3.81 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [7]: timeit mypyc_fib(10) 891 ns ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) In [8]: timeit cython_fib(10) 44.5 ns ± 0.092 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
mypycのコードはpure pythonよりも悪化しました。 Cythonは速いですね。ループ以下の処理がすべてPython APIを使わないコードに落ちている雰囲気があります。 ちなみにfloat(cythonではdouble)に変えたのは特に意味はありません。
まとめ
mypycの高速化はまだまだこれからだと思いますが、型ヒントのついたコードがとりあえずmypyc挟むだけで速くなるなら嬉しいですね。 実はmypyc互換で大幅に効率的なコードを生成するツールを今実装しているので、それも出来上がってきたらまたここで紹介したいなと思います。
Kubeflow/KatibがGoptunaを使った最適化に対応しました。
KubeflowのKatibというハイパーパラメーター最適化等を担当するコンポーネントにGoptunaを使ったSuggestion serviceを実装しました。
Goptunaはハイパーパラメーター最適化ライブラリとして、機能面でも実装品質の面でもPythonで人気のライブラリに劣らないものになってきたかなと思う一方で、Goの機械学習ユーザーはまだまだ少なく、その中でも学習までGoでこなしている人はさらに絞られるので、せめてこういった方面で使われていくと嬉しいなと思います。ブラックボックス最適化フレームワークとしていろんな用途に利用できるソフトウェアなのでみなさんもぜひ触ってみてください。
Katibの基本的な使い方
Katibは基本的に特定の言語やフレームワークに依存しないように設計されています。パラメーターや評価値の受け渡しをどうやっているかというと、コマンドライン引数などからパラメーターを受け取り、目的関数の評価値を予め決めておいたフォーマットで標準出力に出したり、ログファイルとして保存したりします。例として f(x1, x2) = (x1-5)^2 + (x2+5)^2 を目的関数として用意しました (GitHub: https://github.com/c-bata/katib-goptuna-example)。
import argparse import logging logging.basicConfig(filename='/var/log/katib.log', level=logging.DEBUG) def main(): parser = argparse.ArgumentParser() parser.add_argument("--x1", dest='x1', type=float) parser.add_argument("--x2", dest='x2', type=float) args = parser.parse_args() evaluation = (args.x1 - 5) ** 2 + (args.x2 + 5) ** 2 logging.info(f'{{metricName: evaluation, metricValue: {evaluation:.4f}}};') if __name__ == '__main__': main()
FROM python:3-alpine ADD main.py /usr/src/main.py WORKDIR /usr/src
この関数を最適化する際にExperiment CRを作成します。OptunaでいうところのStudyに対応するものです (昔はStudyと呼ばれていたのか、コード読んでるとStudyって書かれてるところもありますが、詳細はまだよく分かっていません)。
Experiment CRが作成されると、パラメーターを変えながらKubernetes Jobを何個も作成し先程のPythonファイルを実行します。各パラメータによる試行はTrialと呼ばれます。Experiment CRで指定するのはざっくり次のような項目です。
- 目的関数の評価回数や並列数など
- 目的関数に与えるパラメーターの探索範囲
- 探索アルゴリズム (文字列で
tpeやcmaesを指定)- 各アルゴリズムがどのSuggestion serviceに対応するかは、
katib-config.yamlで指定します。 - デフォルトは https://github.com/kubeflow/katib/blob/master/manifests/v1alpha3/katib-controller/katib-controller.yaml です。
- 質的変数を探索空間に含む場合には
tpeを利用する方が多いかと思いますが、デフォルトではhyperoptベースのsuggestion serviceが利用されます。Goptunaにもtpeが実装されているので、対応するイメージをGoptuna suggestion serviceのイメージに書き換えればCMA-ESだけでなくTPEでもGoptunaを利用します。
- 各アルゴリズムがどのSuggestion serviceに対応するかは、
- metricscollectorがどのファイルからどういう形式で評価値を取り出すか
- Kubernetes Jobのmanifest template。どういうふうにコマンドライン引数からパラメーターを与えるかはここで指定できます。
具体例は次のとおりです。
apiVersion: "kubeflow.org/v1alpha3" kind: Experiment metadata: namespace: kubeflow labels: controller-tools.k8s.io: "1.0" name: example spec: objective: type: minimize goal: 0.001 objectiveMetricName: evaluation algorithm: algorithmName: cmaes metricsCollectorSpec: source: filter: metricsFormat: - "{metricName: ([\\w|-]+), metricValue: ((-?\\d+)(\\.\\d+)?)}" fileSystemPath: path: "/var/log/katib.log" kind: File collector: kind: File parallelTrialCount: 2 maxTrialCount: 250 maxFailedTrialCount: 3 parameters: - name: x1 parameterType: double feasibleSpace: min: "-10" max: "10" - name: x2 parameterType: double feasibleSpace: min: "-10" max: "10" trialTemplate: goTemplate: rawTemplate: |- apiVersion: batch/v1 kind: Job metadata: name: {{.Trial}} namespace: {{.NameSpace}} spec: template: spec: containers: - name: {{.Trial}} image: docker.io/cbata/hello-katib-quadratic-function command: - "python3" - "main.py" {{- with .HyperParameters}} {{- range .}} - "--{{.Name}} {{.Value}}" {{- end}} {{- end}} restartPolicy: Never
準備に必要なファイルはこれだけです。あとは Katib リポジトリにある、 scripts/v1alpha3/deploy.sh を実行してKatib controller等を立ち上げ、上記のExperiment CRDを適用すれば最適化が実行されます。
試行結果は kubectl port-forward svc/katib-ui -n kubeflow 8080:80 を実行してKatib UI https://localhost:8080/katib をブラウザで開いて確認できます。

Suggestion serviceの実装
Suggestion serviceは、過去のtrialsを受け取り次に探索すべきパラメーターを返すgRPCのサーバーです。 基本的にKatibを利用する上では知る必要はそんなにないので、適宜読み飛ばしてください。 Katibの動作の流れは次の画像にまとまっています。

katib/suggestion.md at master · kubeflow/katib · GitHub
Experimentの作成後、Experimentで指定されたalgorithmNameをもとに katib-config から対応するSuggestion serviceのImageを特定し、Katib controllerがSuggestion CRをapply、Suggestion CRがSuggestion serviceのdeploymentをapplyしPodが生成されます。
Suggestion serviceがreadyになったあと、Katib controllerは過去の試行結果を入力にして次に探索するパラメーターを取得する GetSuggestions() gRPC エンドポイントを何度も叩いてきます。Suggestion controllerはsuggestion serviceを1台しか立ち上げないため、各workerが勝手に解をサンプルしていくOptunaやGoptunaと比べアルゴリズムは実装しやすいなと思いました。Suggestion serviceを実装する際に問題になりやすいのは、Katib controllerがExperimentに紐づけて保持する過去の試行結果と、Goptunaの内部状態をどうやって同期するかです。
Katibの設計ではSuggestion serviceはただパラメーターをサンプルし、Katib controllerに伝えます。その後Katib controllerがtrialを生成し、一意なIDであるtrial nameを生成します。Suggestion serviceからみたときに、自分が生成したパラメーターにどのtrial nameが紐づくかを特定する方法は基本的にありません。TPEやRandom search、Gaussian Processなどこれまでサポートされてきた多くの最適化手法ではこれは問題になりませんが、CMA-ESは別です。
CMA-ESは、多変量正規分布を用意しその分布から解を生成、その評価値をもとに多変量正規分布のパラメーターをよりよい解をサンプルする分布へと更新します。分布が更新されるごとに世代番号がインクリメントされ、分布の更新に利用する解はかならず同じ世代番号の分布からサンプルされている必要があります。分布の世代番号はGoptunaのTrialのメタデータとして紐付けているため、Goptuna TrialとKatib Trialを適切に紐付ける必要があります。
現状ではGoptunaのStudyとは別に trialMapping map[str]int という変数を用意して、Katibのtrial name (str)からGoptunaのtrial ID (int)へのmappingを用意し、 trialMapping にまだ紐付けされていないtrialの中からパラメーターが完全に一致したものをtrialMappingへ追加しています。初期の実装ではKatib-controllerとのやりとりの際に生じる桁落ちを懸念して、パラメーターどうしのマンハッタン距離から最も似ているtrialを紐付けていましたが、Katibはprotobufの定義も(おそらくetcdかなにかに保存するときも)内部表現は全て文字列です。そのため桁落ちなどの心配がなく完全一致でチェックすることにしました。あらためて考えるとTrialのパラメーター表現を文字列で統一するのはかなりわかりやすくリーズナブルだなと思います。
あと実装してから気づいたのですが、よく見たらSuggestion serviceを実装するためのドキュメントがありました。普段あまりドキュメントに期待していないのですが、ParameterAssignmentsが requestNumber で指定された個数だけパラメーターを返さないといけないこととか気づくのに1時間ぐらい時間溶かしたりしてたので、最初に読んでおくことがおすすめです。
katib/new-algorithm-service.md at master · kubeflow/katib · GitHub
所感と今後の展望
設計的にも面白いソフトウェアだなと思いました。また今はOptunaのcommitterもやっていますが、前の部署にいたときにGoでgRPCのサーバー書いたり、OSSでkube-promptを公開していたりしていたので、スキルセット的にも結構マッチしている気がして開発が楽しかったです。
一方で、運用できるチームはかなり限られるかもしれないなというのが正直な感想です。少し動かしただけでもhyperoptのsuggestion serviceが完全に動かなくなってしまっているデグレがあって、原因探って修正するまでに自分も1晩中頑張ったりして苦労しました。Suggestion serviceがおかしいのか、metricscontrollerがおかしいのか、Katib controllerがおかしいのかを正しく状況に応じて切り分ける必要があり、Katibのコード読んでる人でもない限りなかなか難しいかもしれません。
個人的にはGoptunaをベースにすればKatibとの互換性を保ったままシンプルで運用のしやすいツールができる気もしているので、kubebuilder触りつつまた気が向いたときにでもやってみたいなと思います (NASの対応は、言語やフレームワークに依存せず汎用的に使える便利なツールを設計するのが現状では難しい気がしてるので諦める予定です)。