Double forkによるプロセスのデーモン化と、ファイル変更時の自動サーバーリロードの実装 (Python)
Pythonで約100行のシンプルなWSGIサーバーを書いてみる - c-bata web でWSGIサーバーを作ってみました。 100行程度の非常に簡易的なものでしたが、実際にDjangoアプリケーションを動かすこともできました。 前回作ったWSGIサーバーをもう少し便利に使えるようにいくつか機能を追加したのですが、 その中でもWSGIサーバーに限らず知っておくとよさそうな3つの実装を紹介します。
目次:
- Double Fork によるサーバープロセスのデーモン化
- Pythonファイルの更新に検知してサーバーを自動で再起動する
- 文字列で指定したPythonオブジェクトを動的に読み込んで実行する方法
- 謝辞
Double Fork によるサーバープロセスのデーモン化
WSGIサーバーのように長時間動かすようなプログラムはデーモン化しておきたい場合があります。gunicornでも daemon オプションが用意されていて設定で簡単に切り替えることができます。
ところでバックグラウンドで実行するだけなら端末上でコマンドを入力した後に & をつけることもできます。
デーモン化とはなにか違うのでしょうか。少し試してみましょう。
$ python3.7 -m http.server 8000 & [1] 37682 a14737: ~ $ Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
この例では & をつけたことでバックグラウンドになり、別のコマンドを実行できる状態になりましたが、標準ストリームはまだ繋がっていてプロセスの出力が表示されてしまっています。例えば localhost:8000 にアクセスしてみると 127.0.0.1 - - [29/Sep/2018 22:51:32] "GET / HTTP/1.1" 200 - のログがこの端末上に流れます。これ以外にもいくつか問題が残っていて、プログラムによってはSSH接続を切ったときに送られる SIGHUP を受け取ると終了してしまいます。デーモン化というのはこのようにただバックグラウンドにするわけではなく、プロセスから制御端末(tty)を完全に切り離します。
制御端末からプロセスを切り離すために有効なのは setsid() システムコールです*1。これについて知るためにはプロセスグループやセッションという概念を理解しておく必要があります。ただぐぐると詳しい記事が出てくるので詳しい説明はそちらにおまかせします *2。
サーバーにログインすると、ログインセッションが作られます。このセッションのリーダーであるプロセス1つが制御端末(tty)とやり取りを行います。システムコール setsid() を呼び出すと新しいセッションを作成しそのセッショングループのリーダーになります。ここで作成されたセッションはまだ制御端末(tty)を取得していないのでプロセス上に制御端末がなくなったことになります。ただこのとき2つ注意点があります。
- もし
setsid()システムコールを呼び出したプロセスが、プロセスグループリーダーだった場合はエラーが返ってきます。 setsid()を呼ぶことで新しいセッションのセッショングループリーダーになりますが、セッショングループリーダーは唯一制御端末とやりとりすることが可能です。プログラムの実装によってはあとで制御端末を取得してしまうかもしれません。
下図に示す「double fork」と呼ばれるテクニックを利用することでこの2つの懸念が解消されます。

double fork の名の通り、2回 fork(2) を呼び出します。
- 最初に子プロセスを生成した後、親プロセス側で
sys.exit(0)を呼びすぐに終了する。子プロセス側は必ずグループリーダーではないため、setsid()システムコールが呼び出せます。 - 子プロセス側で
sys.setsid()を呼び出し、セッショングループリーダーになり制御端末から切り離します。しかしこの子プロセスはセッショングループリーダーです。さらに孫プロセスを生成し、セッショングループリーダーである子プロセスを終了してしまえば、このセッションに制御端末が取得されることはありません。
ソースコードは次のとおりです。
# https://github.com/kobinpy/kwsgi/pull/2 def daemonize(): """Detaches the server from the controlling terminal and enters the background.""" if os.fork(): # Exit a parent process because setsid() will be fail # if you're a process group leader. sys.exit(0) # Detaches the process from the controlling terminal. os.setsid() if os.fork(): sys.exit(0) # Continue to run application if directory is removed. os.chdir('/') # 0o22 means 755 (777-755) os.umask(0o22) # Remap all of stdin, stdout and stderr on to /dev/null. # Please caution that this way couldn't support following execution: # $ kwsgi ... > output.log 2>&1 os.closerange(0, 3) fd_null = os.open(DEVNULL, os.O_RDWR) if fd_null != 0: os.dup2(fd_null, 0) os.dup2(fd_null, 1) os.dup2(fd_null, 2)
Pythonファイルの更新に検知してサーバーを自動で再起動する
開発用途のサーバーとしては、ファイルの更新を検知して自動でサーバーが再起動してくれると便利そうです。 これは実装が少しだけ複雑ですが、面白い実装になっています。 ソースコードも少し長くなるので細かい解説までは今回は省くことにしましたが、ソースコードにコメントを多めに入れたので読んでみてください。 このプログラムのポイントは次のあたりです。
- Pythonが読み込んだモジュールのファイル一覧と最終更新時刻を取得する
sys.modulesから読み込んでいるモジュールの一覧を取得getattr(module, '__file__')を読み出し、os.path.existsでファイルの存在をチェックos.stat(path).st_mtimeより最終更新時刻を取得する。
- 呼び出しコマンドをサブプロセスでもう一回実行してWSGIサーバーを実行するワーカープロセスを生成する
- メインプロセスとワーカープロセスのやりとりは
tmp領域に作成したファイルを経由して行う
import os import sys import threading import time import _thread import subprocess import tempfile # For reloading server when detected python files changes. EXIT_STATUS_RELOAD = 3 class FileCheckerThread(threading.Thread): def __init__(self, lockfile, interval): threading.Thread.__init__(self) self.daemon = True self.lockfile, self.interval = lockfile, interval self.status = None # 'reload', 'error' or 'exit' def run(self): files = dict() # sys.modules からPythonモジュールの一覧を取得 for module in list(sys.modules.values()): # __file__ が定義されていればそこからファイルパスが取得できる。 path = getattr(module, '__file__', '') if path[-4:] in ('.pyo', '.pyc'): path = path[:-1] if path and os.path.exists(path): files[path] = os.stat(path).st_mtime while not self.status: # lockfile が削除 or 更新されていたら status を 'error' にして例外をraiseして通知する. if not os.path.exists(self.lockfile) or \ os.stat(self.lockfile).st_mtime < time.time() - self.interval - 5: self.status = 'error' _thread.interrupt_main() for path, last_mtime in files.items(): if not os.path.exists(path) or os.stat(path).st_mtime > last_mtime: # ファイルが更新されていたら status を 'reload' にセットして例外をraiseして通知する。 self.status = 'reload' _thread.interrupt_main() break time.sleep(self.interval) def __enter__(self): self.start() def __exit__(self, exc_type, *_): if not self.status: self.status = 'exit' # silent exit self.join() return exc_type is not None and issubclass(exc_type, KeyboardInterrupt) class AutoReloadServer: def __init__(self, func, args=None, kwargs=None): self.func = func self.func_args = args self.func_kwargs = kwargs def run_forever(self, interval): # メインプロセスから呼び出された子プロセスには 'KWSGI_CHILD' 環境変数が存在。 # 無限に呼び出されてしまうため、環境変数で子プロセスであることを教える if not os.environ.get('KWSGI_CHILD'): lockfile = None try: fd, lockfile = tempfile.mkstemp(prefix='kwsgi.', suffix='.lock') os.close(fd) # We only need this file to exist. We never write to it while os.path.exists(lockfile): # ユーザーが端末で実行したプログラムをもう一度実行する。 args = [sys.executable] + sys.argv environ = os.environ.copy() # 無限に呼び出されてしまうため、環境変数で子プロセスであることを教える environ['KWSGI_CHILD'] = 'true' # ワーカープロセスとのやり取りに用いるファイルも環境変数で渡す。 environ['KWSGI_LOCKFILE'] = lockfile p = subprocess.Popen(args, env=environ) while p.poll() is None: # Busy wait... os.utime(lockfile, None) # Alive! If lockfile is unlinked, it raises FileNotFoundError. time.sleep(interval) # 終了ステータスをチェックする。Reload(3) 以外なら終了する。 if p.poll() != EXIT_STATUS_RELOAD: if os.path.exists(lockfile): os.unlink(lockfile) sys.exit(p.poll()) except KeyboardInterrupt: pass finally: if os.path.exists(lockfile): os.unlink(lockfile) return # ワーカープロセスの処理を記述する # ワーカープロセスはコマンド呼び出し時、 KWSGI_LOCKFILE を環境変数で指定する。 # lockfileを通してメインプロセスと通信する。ファイルが削除されていたら終了。ファイルが更新されていたらリロードを意味する。 try: lockfile = os.environ.get('KWSGI_LOCKFILE') bgcheck = FileCheckerThread(lockfile, interval) with bgcheck: self.func(*self.func_args, **self.func_kwargs) if bgcheck.status == 'reload': sys.exit(EXIT_STATUS_RELOAD) except KeyboardInterrupt: pass except (SystemExit, MemoryError): raise except: time.sleep(interval) sys.exit(EXIT_STATUS_RELOAD)
次のように使います。
server = AutoReloadServer(something_func, kwargs={'app': app, 'host': host, 'port': port})
server.run_forever(interval)
Bottleの実装を参考に勉強したのですが、lockfileによるプロセス間のステータスのやりとりや、環境変数を使ったワーカープロセスの判定は自分にとって珍しく面白い実装でした。kwsgiでは次のファイルで実装しています。
文字列で指定したPythonオブジェクトを動的に読み込んで実行する方法
最後は、コマンドラインアプリケーションをつくるときに知っておくと便利なTipsです。 gunicorn や uWSGI といったWSGIサーバーのコマンドラインインターフェイスでは、実行対象のファイル名とそこに書かれてあるWSGIアプリケーションをコマンドライン引数で指定します。
# hello.py def application(env, start_response): start_response("200 OK", [("Content-Type", "text/plain")] return [b"Hello World"]
このようなファイルを用意して、 gunicorn -w 1 hello:application と指定すると、hello.py というファイルを読み込んでからその中にある application と名前のついたオブジェクトを動的に取り出し、WSGIサーバーに読み込ませる必要があります。
やりかたはいくつかありますが、Python3だけを対象にするなら importlib.machinery.SourceFileLoader を使った方法が手軽です。
from importlib.machinery import SourceFileLoader filepath = 'target.py' app_name = 'application' def insert_import_path_to_sys_modules(import_path): abspath = os.path.abspath(import_path) if os.path.isdir(abspath): sys.path.insert(0, abspath) else: sys.path.insert(0, os.path.dirname(abspath)) insert_import_path_to_sys_modules(os.path.abspath(filepath)) module = SourceFileLoader('module', filepath).load_module() app = getattr(t, app_name)
使い方はこのように非常に簡単です。ファイルをモジュールとして動的に読み込み getattr() で対象のオブジェクトを取得します。もしPython 2で同様のことをやるなら importlib が使えないため exec() や compile() 関数を使った少しトリッキーな実装が必要になります。
import types filepath = 'target.py' app_name = 'application' t = types.ModuleType('app') with open(filepath) as config_file: exec(compile(config_file.read(), src.name, 'exec'), t.__dict__) app = getattr(t, app_name)
対象のファイルを open() し、 compile() 関数により動的にファイルの中身をコンパイルしてコードオブジェクトを取得します *3。その後 exec() 関数により types.ModuleType() で用意した変数に module オブジェクトを割り当てます。
こちらの方法を使うことはもうほとんど無いかと思うので、参考までに。ちなみに以前自分が作っていたWSGIフレームワークKobinで、 exec() を使った実装から importlib を使った実装に書き換えたときのコミットは↓のrevisionです、参考までに。
謝辞
自分がdouble forkというものを知ったのは tell-k さんのPyCon JPの発表 Pythonでざっくり学ぶUnixプロセス がきっかけでした。 少し解釈に自信がない部分もあったので、本記事も tell-k さんにレビューいただきました。ありがとうございます。 double forkの2回目のforkをする理由については、別の理由とかではないか少し心配だったのですが tell-kさんも基本的には同じ解釈のようです。 2回目のforkの意図について確認した際に、tell-kさんから次の返事がきました。
私も資料作ってる時に同じ疑問に思いました。そしたら下記リンクにたどり着きましたので共有しておきます。 http://q.hatena.ne.jp/1320139299
setsid = セッションリーダーで、技術的に制御端末の割り当てが可能だから、確実に割り当てできないようにセッションリーダーではない孫を作るっていう認識は私も一緒です。
あとは daemon化とは直接関係なさそうな気はしますが、double fork することで、ゾンビプロセスを抑制できるって話は面白かったです。 http://d.hatena.ne.jp/sleepy_yoshi/20100228/p1
どうやら親が死んで init (システム上の一番最初のプロセス。pid=1, ppid=0)の養子になることが、ゾンビプロセスの発生を抑えることにも繋がっているとのことでした。なぜ init が頻繁にwaitを呼んでいるのか、その理由までは調べきれていませんが参考までに。
他にも今回はgunicornのdouble forkの実装を参考にしました。 gunicornの実装では、 chdir() を呼んでいないのですがこちらの理由もまた分かったらまた追記しておこうかとおもいます。
- gunicorn/util.py at 91974f0f44080fdd6f2885832d101474671c4b9b · benoitc/gunicorn · GitHub
- Unix Programming Frequently Asked Questions - 1. Process Control
今日紹介した実装はどれも書いていて楽しいコードでした。 次は時間があるときにでもWSGIサーバーのパフォーマンス最適化のための方法を勉強してまとめたいなと思います。
Pythonで約100行のシンプルなWSGIサーバーを書いてみる

- 作者:Michal Jaworski,Tarek Ziade
- 発売日: 2018/02/26
- メディア: 単行本
はじめに — Webアプリケーションフレームワークの作り方 in Python の資料が最近になってホットエントリー入りし、思ったよりも多くの方に読んでいただけているようです。見返しているとWSGIサーバーを作りながらHTTPについて学べる章があってもいいかもとふと思いました。書くとすれば内容的には id:shimizukawa さんのPyCon JP 2018の発表をもう少し詳しく説明する資料になりそうな気がします。
PyCon JP 2018: Webアプリケーションの仕組み - 清水川のScrapbox
とはいえ自分もWSGIサーバーを一度も書いたことがないので、気分転換にシンプルなWSGIサーバーを書いてみました。 4時間ぐらいかかるかなと思いながら id:shimizukawa さんの上記の資料のコードをぱくりつつ書いてみたら、1時間ちょっとで最低限動くものが出来ました。その後結局リファクタリングのためにwsgirefやgunicornの実装読んでたら5時間ぐらい使ったのですが、今は手元のDjangoアプリケーションを動かしてみてもPOSTのエンドポイントとか含めてちゃんと動いてくれました。
100行ちょっと超えた程度の実装に落ち着いたので解説もそれほど大変ではなさそう。パフォーマンスの改善やヘッダーを異常に長くしてサーバー詰まらせるようなリクエストの対策などを考えだすと課題はいくらか残っていますが解説用にはちょうどいい実装かなと思います。
import logging import socket import urllib.parse from threading import Thread logger = logging.getLogger(__name__) logger.setLevel(logging.DEBUG) logger.addHandler(logging.StreamHandler()) def worker(conn, wsgi_app, env): with conn: headers = None status_code = None def start_response(s, h): nonlocal headers, status_code status_code = s headers = h wsgi_response = wsgi_app(env, start_response) if headers is None or status_code is None: conn.sendall(b'HTTP/1.1 500\r\n\r\nInternal Server Error\n') return logger.info(f"{env['REMOTE_ADDR']} - {status_code}") status_line = f"HTTP/1.1 {status_code}".encode("utf-8") headers = [f"{k}: {v}" for k, v in headers] response_body = b"" content_length = 0 for b in wsgi_response: response_body += b content_length += len(b) headers.append(f"Content-Length: {content_length}") header_bytes = "\r\n".join(headers).encode("utf-8") env["wsgi.input"].close() # close() does not raise an exception if called twice. conn.sendall(status_line + b"\r\n" + header_bytes + b"\r\n\r\n" + response_body) def make_wsgi_environ(rfile, client_address, port): # should return '414 URI Too Long' if line is longer than 65536. raw_request_line = rfile.readline(65537) method, path, version = str(raw_request_line, 'iso-8859-1').rstrip( '\r\n').split(' ', maxsplit=2) if '?' in path: path, query = path.split('?', 1) else: path, query = path, '' env = { 'REQUEST_METHOD': method, 'PATH_INFO': urllib.parse.unquote(path, 'iso-8859-1'), 'QUERY_STRING': query, 'SERVER_PROTOCOL': "HTTP/1.1", 'SERVER_NAME': socket.getfqdn(), 'SERVER_PORT': port, 'REMOTE_ADDR': client_address[0], 'SCRIPT_NAME': "", 'wsgi.version': (1, 0), 'wsgi.url_scheme': "http", 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.run_once': False, } while True: # should return '431 Request Header Fields Too Large' # if line is longer than 65536 or header exceeds 100 lines. line = rfile.readline(65537) if line in (b'\r\n', b'\n', b''): break key, value = line.decode('iso-8859-1').rstrip("\r\n").split(":", maxsplit=1) value = value.lstrip(" ") if key.upper() == "CONTENT-TYPE": env['CONTENT_TYPE'] = value if key.upper() == "CONTENT-LENGTH": env['CONTENT_LENGTH'] = value env_key = "HTTP_" + key.replace("-", "_").upper() if env_key in env: env[env_key] = env[env_key] + ',' + value else: env[env_key] = value env['wsgi.input'] = rfile return env def serve_forever(app, host="127.0.0.1", port=8000, max_accept=128, timeout=30.0, rbufsize=-1): logger.info(f"Serving HTTP on http://{host}:{port}/") with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True) sock.bind((host, port)) sock.listen(max_accept) while True: conn, client_address = sock.accept() conn.settimeout(timeout) rfile = conn.makefile('rb', rbufsize) env = make_wsgi_environ(rfile, client_address, port) Thread(target=worker, args=(conn, app, env), daemon=True).start() if __name__ == '__main__': from main import app serve_forever(app)
動かすとWSGIアプリケーションから渡されたヘッダーも正しく返しているので、下のようにリダイレクトとかも問題なく動いている。

最近かなりブログの更新頻度が落ちていたので、いつもより雑なネタですが出してみました。
2018/09/23 23:33:00 追記
パクられた!w
— Takayuki Shimizukawa (@shimizukawa) 2018年9月23日
受信byte数が4096byteだとブロックしちゃうバグがあるのだけど、解決するにはコードが複雑になっちゃう。シンプルな解決方法見つけたらおしえてー
この記事で紹介した実装は、socketからreadする長さが4096バイトの整数倍のときに、次の書き込みを期待する実装になっているのでブロックする。ちゃんとハンドリングするならおそらく select とか epoll 使うのが筋ですが、清水川さんの発表資料はトークの対象レベルが結構低めなので非同期I/Oの話を入れられなかったぽい。気が向いたらこっちのサンプルはselect使って修正します。
wsgirefの実装読んでたら、makefileを使ったシンプルな解決策に気づいたのでこの問題修正済みです。
追記おわり
2018/09/24 04:10:00 追記
wsgirefの実装読んでいて知ったのですが、makefileメソッドを使えばファイルライクオブジェクトが返ってくるので、そこから readline() を使って行ベースで読み出せばキレイに解決することに気づきました。パース処理も楽になるし、wsgi.inputも簡単に作れて最高ですhttps://t.co/cOVpNQYd1q https://t.co/zhJxh0U8WQ
— Masashi Shibata (@c_bata_) 2018年9月23日
該当行(wsgiref)
- cpython/socketserver.py at c87d9f406bb23657c1b4cd63017bb7bd7693a1fb · python/cpython · GitHub
- cpython/server.py at c87d9f406bb23657c1b4cd63017bb7bd7693a1fb · python/cpython · GitHub
- cpython/simple_server.py at c87d9f406bb23657c1b4cd63017bb7bd7693a1fb · python/cpython · GitHub
追記おわり
2018/09/25 13:10:00 追記
昼休みにサクッとCLI用意してリポジトリ用意してみた。オートリロードの実装とかimportlib使ったアプリケーションの読み込み実装は昔実装したWSGICLIからコピペでほとんど済みました。
— Masashi SHIBATA (@c_bata_) 2018年9月25日
CLIは $ kwsgi https://t.co/ciFuSBwBAf app --port 8000 --reload みたいに使えます。https://t.co/2ohR8VfAZX
追記おわり
Django における認証処理実装パターン
追記: 翔泳社さんからDjangoの書籍を出版するのでぜひ読んでみてください。

この資料は DjangoCongress JP 2018で話した「Djangoにおける認証処理実装パターン」 の解説記事になります。
2019/04/08 追記: GithubのコードはPython3.7 Django2.2にupdateしています)
何年か前に Djangoのユーザー認証まとめ という記事を書きました。今でもコンスタントに100PV/dayくらいアクセスのある記事なのですが内容が古く、実装時にハマりやすい注意点にもあまり触れることができておらず、おすすめできる資料ではありません。今回はDjangoCongress JPにて発表の機会をいただけたのですが、この機会に認証処理についてまとめ直すと同時にこちらの資料とソースコード(Github)を合わせて用意することにしました。何かのお役にたてば幸いです。
はじめに
フレームワークの中にユーザーモデルまで定義されていることは、Djangoの最も特徴的な点かもしれません。このおかげで認証が必要なアプリケーションを高速に開発することができ、強力な管理画面もすぐに利用できます。しかし、Flask+SQLAlchemyとかでいちからユーザーモデルを定義するケースとは違って、Djangoでは内部の仕組みを正しく把握していないとユーザーモデルを少しカスタマイズをするだけでも思わぬところでエラーが起きたり意図しない挙動となる危険があります。実装に悩んだことのある方も少なくないのではないでしょうか。本資料では認証処理をカスタマイズする際には抑えておかなければいけないポイントや注意するべき落とし穴もできるだけ解説できればと思っています。
スライド
PyCon JP 2017 のDjangoに関する発表の紹介
PyCon JP 2017でも認証や認可に関する発表がありました。それぞれ次のような内容です。
- 「Djangoフレームワークのユーザーモデルと認証」 by tokibito
- 資料: https://www.slideshare.net/tokibito/django-79549364
- 標準の認証処理について、HTTP上で行われるセッション管理の動きも含めて詳しく解説
- 「プロダクト開発してわかったDjangoの深〜いパーミッション管理の話」 by hirokiky
- 資料: https://www.slideshare.net/hirokiky/django-pyconjp2017
- 認可(Authorization)に関する話
そのため今回は認証の カスタマイズ に絞った話をします。
ソースコード
Django 2.2, Python 3.7 で動作するソースコードを用意・Githubで公開しています。リポジトリ内の各PRがそれぞれのトピックのソースコードとなっています。
- 自作認証バックエンドを使ったEmail/Password 認証
- ユーザーモデルのカスタマイズ
- social-auth-core を使ったGithub OAuth認証
- social-auth-core を使わず from scratch で実装した Github OAuth認証
認証処理のカスタマイズ
Djangoの提供する認証機能
まずはDjangoが提供する認証処理についておさらいしましょう。
Djangoの認証処理に関する機能は django.contrib.auth パッケージにまとまっています。
| 用途 | Formクラス | Viewクラス |
|---|---|---|
| ログイン | AuthenticationForm |
LoginView |
| ログアウト | - | LogoutView |
| パスワード更新 | PasswordChangeForm |
PasswordChangeView PasswordChangeDoneView |
| パスワードリセット | PasswordResetForm |
PasswordResetView PasswordResetDoneView PasswordResetConfirmView PasswordResetCompleteView |
| パスワード書き換え | SetPasswordForm |
- |
| ユーザー登録 | UserCreationForm |
- |
参照: Built-in Auth Forms / Built-in Auth View Classes
組み込まれているFormクラスやViewクラスを列挙しましたが、パスワードリセットやパスワード更新用の画面など雑にWebサイト作るときは省略しちゃいそうなものまで標準で用意してくれています。それぞれの機能に関する関数ベースビューも提供されていますが、Django 1.11よりdeprecatedになっているので気をつけてください。また settings.py からは、 LOGIN_URL や LOGIN_REDIRECT_URL 、 LOGOUT_REDIRECT_URL を変更できます。
認証バックエンドによるカスタマイズ
標準では username/password によるログインが有効になっていますが、ここでは試しに email/password によるログインもできるようにしてみましょう。Djangoでは認証バックエンドというクラスを用意してあげれば認証処理を自由に拡張することができます。 django.contrib.auth.authenticate() が呼ばれると、 settings.py の AUTHENTICATION_BACKENDS により指定される認証バックエンドのリストの先頭から順に認証を試みます。1つが失敗しても次の認証バックエンドで認証を試み、全て認証に失敗すると認証失敗となります 1。
それではEメールとパスワードで認証を行う認証バックエンドを定義して、 AUTHENTICATION_BACKENDS に追加してみましょう。
デフォルトでは、
認証バックエンドは2つのメソッドを定義しなければなりません 2。
authenticate(request, **credentials): HttpRequestオブジェクトとあわせて認証に必要な情報を受け取り、ユーザーモデルのオブジェクトを返す。get_user(user_id): ユーザーモデルの主キーを受け取り、ユーザーモデルのオブジェクトを返す。
一見動作するが、問題をかかえた例
それでは実際に認証バックエンドの例をみてみましょう。まずインターネットで検索したときに見かけたあまりおすすめできない例を紹介します。次のように実装してしまう気持ちはすごくわかりますし、自分も初学者のころうっかり実装してしまったことがありました。
from django.contrib.auth import get_user_model from django.contrib.auth.backends import ModelBackend UserModel = get_user_model() class EmailAuthBackend(ModelBackend): def authenticate(self, username="", password="", **kwargs): if username is None: username = kwargs.get(UserModel.USERNAME_FIELD) try: user = UserModel.objects.get(email=username) except UserModel.DoesNotExist: return None else: if user.check_password(password) and self.user_can_authenticate(user): return user
usernameを入力する場所で、Eメールを入力するように変わるだけなので標準のModelBackendをベースにするのが簡単です。 authenticate メソッドだけを愚直に置き換えたこの認証バックエンドは、usernameとemailのどちらを入力しても認証に成功します。usernameとemailのフィールドの扱いが混ざっているこのコードは少しDirtyに見えますが、動作は一見問題なさそうです。 AUTHENTICATION_BACKENDS に追加して動かしてみましょう。
AUTHENTICATION_BACKENDS = [
'django.contrib.auth.backends.ModelBackend',
'accounts.backends.EmailAuthBackend', # 追加
]
実際これは基本的にうまく動きます。フォームのラベルが username となってしまっていることだけ修正してあげれば、問題ないように見えますが実は1点無視できない問題があります。ログインフォーム上では username フィールドを入力する場所ですので、当然username の仕様にあわせたバリデーション処理を通ってきます。標準のusernameの仕様は、 「@」を受け入れますが twitter や github のようにそれを受け入れない仕様に変わった場合この方法は破綻します。
問題を修正した例
次のように定義するのがいいでしょう。
class EmailAuthBackend(ModelBackend): def authenticate(self, request, email=None, password=None, **credentials): try: user = UserModel.objects.get(email=email) except UserModel.DoesNotExist: return None else: if user.check_password(password) and self.user_can_authenticate(user): return user
認証バックエンドは定義できましたが、このバックエンドを設定してもまだログイン画面でEメールを入力してもログインできません。 Eメール用のログインフォームを定義して、そちらを利用する必要があります。
from django import forms from django.contrib.auth import authenticate, get_user_model from django.utils.text import capfirst from django.utils.translation import gettext_lazy as _ UserModel = get_user_model() class EmailAuthenticationForm(forms.Form): email = forms.EmailField(max_length=254, widget=forms.TextInput(attrs={'autofocus': True})) password = forms.CharField(label=_("Password"), strip=False, widget=forms.PasswordInput) error_messages = { 'invalid_login': "Eメールアドレス または パスワードに誤りがあります。", 'inactive': _("This account is inactive."), } def __init__(self, request=None, *args, **kwargs): self.request = request self.user_cache = None super().__init__(*args, **kwargs) # Set the label for the "email" field. self.email_field = UserModel._meta.get_field("email") if self.fields['email'].label is None: self.fields['email'].label = capfirst(self.email_field.verbose_name) def clean(self): email = self.cleaned_data.get('email') password = self.cleaned_data.get('password') if email is not None and password: self.user_cache = authenticate(self.request, email=email, password=password) if self.user_cache is None: raise forms.ValidationError( self.error_messages['invalid_login'], code='invalid_login', params={'email': self.email_field.verbose_name}) else: self.confirm_login_allowed(self.user_cache) return self.cleaned_data def confirm_login_allowed(self, user): if not user.is_active: raise forms.ValidationError(self.error_messages['inactive'], code='inactive') def get_user_id(self): if self.user_cache: return self.user_cache.id return None def get_user(self): return self.user_cache
用意できたら、ログイン用の Formクラスとして差し込みましょう。
from django.contrib.auth.views import LoginView from django.urls import path from accounts import views from accounts.forms import EmailAuthenticationForm urlpatterns = [ path('login/', LoginView.as_view(form_class=EmailAuthenticationForm, template_name='accounts/login.html'), name='login'), : ]
このようにして Email/Password の実装ができます。 username と email のフィールドを混同せずしっかり別のものとして扱う点に注意してください。
ユーザーモデルのカスタマイズ
認証処理をカスタマイズしようとする際に、セットで悩むことが多いのがユーザーモデルのカスタマイズ方法です。
ユーザーモデルの拡張方法
ユーザーモデルの拡張方法はいくつかあります。
- Userモデルに対して 1対1 の関係を持つUserProfileモデルを定義する
- AbstractUser, AbstractBaseUser のサブクラスを定義する
それぞれ一長一短があるため、必要に応じて使い分けてください。
1対1の関係をもつモデルを定義する
UserProfileモデルを定義する方法は、次のように1対1の関係を持つモデルを用意します 3。
class UserProfile(models.Model): user = models.OneToOneField(settings.AUTH_USER_MODEL) some_additional_columns1 = models.SomethingField(...) :
扱うデータの性質に応じてDB設計上の議論もあるかと思いますが、このやり方を採用したときの特徴は次のとおりです。
- カラムの追加定義のみが可能
first_nameやlast_nameのようにサービスによっては不要なカラムがあるかと思いますが、これらを減らす際は後述する AbstractBaseUser クラスを継承して定義する必要があります
- ユーザーモデルに直接手を加える必要がない
- 例えばサードパーティのライブラリがユーザーに紐づく情報を追加したいときは、この点が大きなメリットとなります
- また後述するAbstractBaseUserやAbstractUserによるカスタマイズと共存可能ですので、必要に応じて使い分けたり両方使ってください。
- テーブルが分かれているので、SELECTする際にはクエリの数を増やすか、JOINする必要がある。
- 扱わなければいけないレコードの数が増える。
- Djangoの
signalsという機能を使うとUserモデル作成時にトリガーしてUserProfileモデルを自動で作成したりすることもできます。この機能を使うと場合によってはUserProfileモデルの管理をあまり意識することなくコーディングができるかもしれません。
- Djangoの
AbstractUser や AbstractBaseUser を継承したユーザーモデルの定義
AbstractUser は AbstractBaseUser を継承してカラム定義やメソッド定義を追加しています。これらは class Meta 内で abstract=True が定義されているため、 makemigrations 実行時にテーブル定義が生成されることはありません。
この2つのClassを継承する方法はどちらもほとんどやり方が変わらないので、今回は AbstractBaseUser を継承してユーザーモデルを定義、参照する方法を解説します。ユーザーモデルにどのようなカラムを定義したいのかをベースに考えてください。
標準のUserモデルは非常に多くのカラムが用意されています。 first_name や last_name などが定義されていますが、個人的につくるサービスでこれらのカラムが必要になることはありません。今回は自分がサービスを実装するときによく使うモデル定義を紹介します。
from django.contrib.auth.base_user import AbstractBaseUser from django.contrib.auth.models import PermissionsMixin, UserManager from django.contrib.auth.validators import ASCIIUsernameValidator from django.core.mail import send_mail from django.db import models from django.utils import timezone from django.utils.translation import ugettext_lazy as _ class User(AbstractBaseUser, PermissionsMixin): username_validator = ASCIIUsernameValidator() username = models.CharField( _('username'), max_length=150, unique=True, help_text=_('Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.'), validators=[username_validator], error_messages={ 'unique': _("A user with that username already exists."), }, ) email = models.EmailField(_('email address'), blank=True) profile_icon = models.ImageField(_('profile icon'), upload_to='profile_icons', null=True, blank=True) self_introduction = models.CharField(_('self introduction'), max_length=512, blank=True) is_admin = models.BooleanField(default=False) is_staff = models.BooleanField( _('staff status'), default=False, help_text=_('Designates whether the user can log into this admin site.'), ) is_active = models.BooleanField( _('active'), default=True, help_text=_( 'Designates whether this user should be treated as active. ' 'Unselect this instead of deleting accounts.' ), ) date_joined = models.DateTimeField(_('date joined'), default=timezone.now) objects = UserManager() EMAIL_FIELD = 'email' USERNAME_FIELD = 'username' REQUIRED_FIELDS = ['email'] class Meta: verbose_name = _('user') verbose_name_plural = _('users') db_table = 'users' def clean(self): super().clean() self.email = self.__class__.objects.normalize_email(self.email) def email_user(self, subject, message, from_email=None, **kwargs): send_mail(subject, message, from_email, [self.email], **kwargs)
Djangoに詳しい方は get_short_name() と get_full_name() メソッドが定義されてないじゃないかと感じるかもしれませんが、Django 2.0からは定義する必要がありません。
ユーザーモデルの差し替え
定義したモデルは settings.py の AUTH_USER_MODEL で app_label.ModelName の形式で指定します。
AUTH_USER_MODEL = 'accounts.User'
注意点としては、マイグレーションを実行した後の AUTH_USER_MODEL の差し替えは、多対多や外部キーの解決が難しくが非常に複雑になります。あとからマイグレーションをする必要がないよう、 AUTH_USER_MODEL によってユーザーモデルを差し替える作業は出来るだけシステムを稼働前に行ってください。
また会員登録時に UserCreationForm を使っていますが、これは username が絡む都合上デフォルトではAbstractBaseUser を継承したカスタムモデルで利用できません(AbstractUserは使えます)。次のように、 Meta.models で自作のモデルを指定した UserCreationForm を用意して利用しましょう。
今回は使っていませんが、UserChangeFormについても同様です。
from django.contrib.auth.forms import ( UserCreationForm as BaseUserCreationForm, UserChangeForm as BaseUserChangeForm, ) from .models import User class UserCreationForm(BaseUserCreationForm): class Meta(BaseUserCreationForm.Meta): model = User class UserChangeForm(BaseUserChangeForm): class Meta(BaseUserChangeForm.Meta): model = User
usernameの取扱いに関する注意点
さてユーザーモデルの定義の解説は、非常に簡単で解説も非常に短いものでした。そのため今回はDjangoのユーザーモデルを定義する際に注意しておいて欲しい username の話をしようと思います。
以前のDjangoのバージョンでは、Python2を使っているときはASCII文字と数字、Python3を使っているときは unicode 文字が username に使うことができました。しかし、Django 2.0 における大きな変更としてPython 2サポートの終了があります。その上で次の質問に答えてください。
「c-bаtа」と「c-bata」、この2つは同じ username でしょうか?
$ python3 >>> "c-bata" == "c-bаtа" False
一見同じに見えるこの2つの文字列はunicode上は別の文字です。
左辺に表示されている a という文字は U+0061 LATIN SMALL LETTER A ですが、右辺の а という文字は U+0430 CYRILLIC SMALL LETTER A です。punycode に encode することで紛らわしい文字がよくわかります。
>>> "c-bаtа".encode('punycode') b'c-bt-73db' >>> "c-bata".encode('punycode') b'c-bata-' >>>
別の文字ということは、それぞれ別のユーザーとして登録可能であることを示しています。これはなりすましといった何らかの攻撃に利用されるかもしれません。そのため先程定義したモデルのように username には ASCIIUsernameValidator を指定しておくことは、悩みごとの少なくなるいいテクニックです。仕様上問題なければぜひ付けておきましょう。
from django.contrib.auth.validators import ASCIIUsernameValidator class User(AbstractBaseUser, PermissionsMixin): username_validator = ASCIIUsernameValidator() username = models.CharField(_('username'), validators=[username_validator], ... ) :
またもう少し細かく制限するのもいいかもしれません。ハイフンとアンダースコアを別々としていては c-bata さんと c_bata さんが存在可能です。
個人的には次のようなvalidatorがおすすめです。
import re from django.core import validators from django.utils.deconstruct import deconstructible @deconstructible class UsernameValidator(validators.RegexValidator): regex = r'^[a-z0-9-]+$' message = ( 'Enter a valid username. This value may contain only' ' English small letters, numbers and hyphen.' ) flags = re.ASCII
from django.core.exceptions import ValidationError from django.test import TestCase from accounts.validators import UsernameValidator class UsernameValidatorsTests(TestCase): def test_username_validator(self): valid_usernames = ['glenn', 'jean-marc001', 'c-bata'] invalid_usernames = ['c_bata_', 'GLEnN', "o'connell", 'Éric', 'jean marc', "أحمد"] v = UsernameValidator() for valid in valid_usernames: with self.subTest(valid=valid): v(valid) for invalid in invalid_usernames: with self.subTest(invalid=invalid): with self.assertRaises(ValidationError): v(invalid)
unicodeには他にも多くのパターンがあり複雑ですが、 unicodedata パッケージを使って次のように正規化しておくといいでしょう。
UserCreationFormでは内部でこの処理を読んでいますが、UserCreationForm を使わず自分たちでバリデーションしてるようなコードや REST Framework の Serializer を作っている例などを見るとこの処理を忘れている例がしばしばあります。気をつけておきましょう。
>>> import unicodedata >>> unicodedata.normalize('NFKC', 'アアァ') 'アアァ' >>> unicodedata.normalize('NFKC', '㌀') 'アパート' >>> unicodedata.normalize('NFKC', '9⁹₉⑨') '9999' >>> unicodedata.normalize('NFKC', 'Hℍℌ') 'HHH'
仕様上どうしてもUnicodeを使いたいという人は、The Tripartite Identity Pattern などを参考に設計を見つめ直してみてもいいかもしれません。
GithubによるOAuth認証
追記: 自分の勉強不足だったのですが、django-allauthはあらためて実装読んでみると複雑性を抑えつつよくできている印象です。自分が次実装するならこちらを使いそうです。あまりこれより下の内容は参考にしないほうがいいかもしれません。
python-social-auth(social-auth-core) の紹介
1つだけならまだいいですが、複数のOAuthプロバイダーをサポートしたい場合、twitterやgithub、Facebook全てのAPIを調べて自分で実装するのは少し面倒です。python-social-auth(social-auth-core)という人気のライブラリがあり、 social-auth-app-django というDjangoアプリケーションまで公開しています。今回はこちらを使ったOAuth認証の実装を解説します。
social-auth-core 4 は、様々なORM、フレームワーク、OAuthプロバイダーに対応するため抽象化のためのStorageやStrategy、Pipelineという独自の概念があります。今回紹介するproviderでは必要のないNonceなどのモデルも同時に作成されてしまいます。これらの概念とあわせて実装を理解するのは、Djangoに少し慣れたプログラマーであったとしても少々苦労するでしょう。データベースの状態をシンプルに保つことはアプリケーションの保守性を高める上で非常に重要です。Python界の巨匠 石本さんも次のようにおっしゃっています。

対応したいOAuthプロバイダーの数が少なく、social-auth-coreの理解に時間をかけたくない場合は、自前で実装するという選択も検討してみるといいかもしれません。social-auth-coreを使わずにGithub OAuth認証をする例を用意しました。これから紹介する認証フローを理解していれば、読めると思いますので今回は詳しく解説しませんが自分で実装が必要なときは参考にしてください。
https://github.com/c-bata/django-auth-example/pull/4
OAuth認証の流れ
Githubを例にOAuth認証のおおまかな流れを簡単に解説します。

データベースの定義
まずはデータベースの構成について考えます。方法は1つではありませんが、基本的には次のようにデータベースをわけるでしょう。

- id: 主キー
- user_id: ユーザーモデルとのひもづける外部キー
- provider: 'github' や 'facebook' などOAuthプロバイダーの識別子
- uid: プロバイダーのシステム上でユーザーの識別に使われている一意な値
今回は同じSocialアカウントが別々のレコードで登録されないように、providerとuidでunique togetherの制約を付与しています。 これをDjangoのModel定義に落とし込むと次のようになります。
from django.conf import settings from django.db import models class Social(models.Model): """Social Auth association model""" user = models.ForeignKey(settings.AUTH_USER_MODEL, related_name='socials', on_delete=models.CASCADE) provider = models.CharField(max_length=32) uid = models.CharField(max_length=255) class Meta: unique_together = ('provider', 'uid') db_table = 'socials'
social-auth-core を使った実装
次は social-auth-core をインストールして設定していきましょう。 今回はGithub OAuthを実装していきます。
$ pip install social-auth-core==1.7.0 social-auth-app-django==2.1.0
インストールが出来たら settings.py を変更していきます。
social_app_django が、Djangoのアプリケーションであると説明しましたが social-core の方もDjangoを意識したデザインになっていて、social_core のbackendsと呼ばれる概念はDjangoの認証バックエンドとしての仕様を満たしています。
今回はGithubなので、次のように AUTHENTICATION_BACKENDS を設定してください。
INSTALLED_APPS = [
:
'social_django',
'socials.apps.SocialsConfig',
]
AUTHENTICATION_BACKENDS = (
'django.contrib.auth.backends.ModelBackend',
'social_core.backends.github.GithubOAuth2',
)
TEMPLATES = [
{
'OPTIONS': {
'context_processors': [
:
'socials.context_processors.backends',
'socials.context_processors.login_redirect',
],
},
},
]
SOCIAL_AUTH_GITHUB_KEY = os.getenv("SOCIAL_AUTH_GITHUB_KEY", "")
SOCIAL_AUTH_GITHUB_SECRET = os.getenv("SOCIAL_AUTH_GITHUB_SECRET", "")
GithubのApplication KeyとApplication Secretが必要です。 Github Settingsから登録を行いましょう。コールバックURLは次のように http://127.0.0.1:8000/social/complete/github とします。

次はCallback等のエンドポイントを追加していきます。URLは social-app-django に習って次のようにしました。
from django.urls import path from socials import views app_name = 'social' urlpatterns = [ path("login/<provider>", views.auth, name="begin"), path("complete/<provider>", views.complete, name="complete"), path("disconnect/<provider>", views.disconnect, name="disconnect"), path("disconnect/<provider>/<int:association_id>", views.disconnect, name="disconnect_individual"), ]
プロジェクトの urls.py でincludeもしておきます。
urlpatterns = [
:
path("social/", include("socials.urls")),
path('admin/', admin.site.urls),
]
次は view関数を定義します。
from django.conf import settings from django.contrib.auth import REDIRECT_FIELD_NAME, login from django.http import Http404 from django.urls import reverse from django.views.decorators.cache import never_cache from social_core.actions import do_auth, do_complete, do_disconnect from social_core.backends.utils import get_backend from social_core.exceptions import MissingBackend from social_django.strategy import DjangoStrategy from social_django.models import DjangoStorage from social_django.views import _do_login as login_func BACKENDS = settings.AUTHENTICATION_BACKENDS @never_cache def auth(request, provider): redirect_uri = reverse("social:complete", args=(provider,)) request.social_strategy = DjangoStrategy(DjangoStorage, request) try: backend_cls = get_backend(BACKENDS, provider) backend_obj = backend_cls(request.social_strategy, redirect_uri) except MissingBackend: raise Http404('Backend not found') return do_auth(backend_obj, redirect_name=REDIRECT_FIELD_NAME) @never_cache def complete(request, provider): redirect_uri = reverse("social:complete", args=(provider,)) request.social_strategy = DjangoStrategy(DjangoStorage, request) try: backend_cls = get_backend(BACKENDS, provider) backend_obj = backend_cls(request.social_strategy, redirect_uri) except MissingBackend: raise Http404('Backend not found') return do_complete(backend_obj, login_func, request.user, redirect_name=REDIRECT_FIELD_NAME, request=request) @never_cache def disconnect(request, provider, association_id=None): request.social_strategy = DjangoStrategy(DjangoStorage, request) try: backend_cls = get_backend(BACKENDS, provider) backend_obj = backend_cls(request.social_strategy, "") except MissingBackend: raise Http404('Backend not found') return do_disconnect(backend_obj, request.user, association_id, redirect_name=REDIRECT_FIELD_NAME)
ログイン画面に Github によるログインボタンを追加。
<a href="{% url 'social:begin' 'github' %}">Github でログイン</a>
Pipeline の仕組み
Pipeline は python-social-core の最も優れた概念です。Pipelineは、OAuthの流れの中でいくつかのポイントに処理を差し込めるフックポイントを提供してくれます。
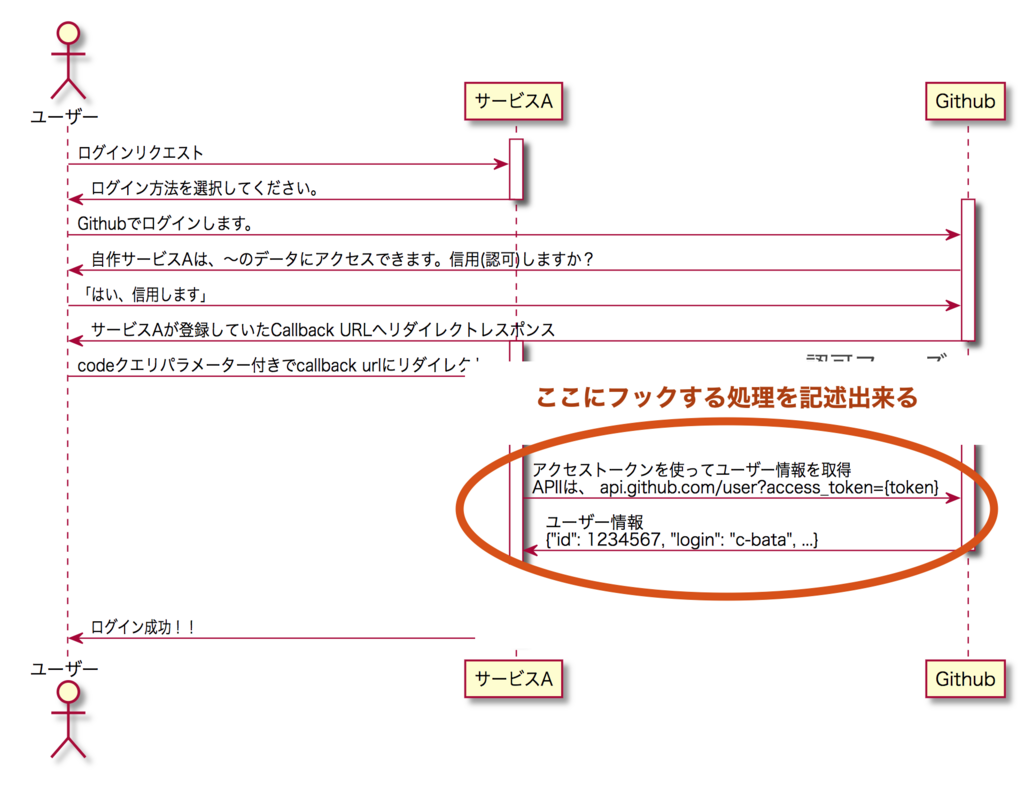
例えば↑のポイントにフックして処理を記述することができますが、これは何が嬉しいのでしょうか? OAuthプロバイダーのシステム上での表現と自分たちのサービスの表現にはいくつか違いがあります。 例えば、FacebookがGenderを50種類以上用意しているのに対して、自分たちのサービスでは 2-4 種類しか定義したくないこともあるでしょう。プロフィール画像URLのスキームが http の場合、Mixed Contentを避けるために画像をダウンロードしてhttpsのエンドポイントで自前でホストする必要があるケースもあるかもしれません。
# pipeline.py def save_profile(backend, user, response, *args, **kwargs): if backend.name == 'facebook': user.gender = sanitize_gender(response.get('gender')) : profile.save()
定義したPipelineは次のように設定します。
SOCIAL_AUTH_PIPELINE = (
'app_label.pipeline.save_profile',
:
)
こういった外部のサービスから取得するユーザー情報を自分たちのサービスに合わせて加工することができます。簡単に拡張できるようになっているので、ぜひドキュメント を参考に利用してみてください。
まとめ
Djangoにおけるユーザー認証のカスタマイズにフォーカスして解説を行いました。 誰も教えてくれないはまりどころもありますので、この資料を参考に進めてください。
-
ユーザは一度認証されると、Djangoはどのバックエンドで認証されたのかをユーザーセッションに保存します。セッションが有効な場合は、同じバックエンドを利用する時にキャッシュとしてそのユーザーが認証済みかどうかチェックします。強制的に別の方法で再度認証させたい場合は、セッションデータをクリアしてください。クッキーを削除するか、
Session.objects.all().delete()で消すことができます。↩ -
認証バックエンドには、
has_permやget_all_permissionsといったユーザーオブジェクトの権限確認(認可)のためのメソッドを定義することもできます。ただし、話が大きくなりすぎるため今回は扱いません。↩ -
ユーザーモデルを外部キーとするときに
get_user_modelでもできそうに見えますが、こちらはimport loopが発生する問題があるので避けてください。settings.AUTH_USER_MODELを使いましょう。↩ -
特にpython-social-authの実装は social-core の意味のないラッパーのようになっていて、一見あまり綺麗でないように感じました。これは python-social-auth が悪いというわけではなく、人気のあるライブラリが後方互換を保ったまま初期の設計の負債を修正するにはこのようにならざるを得なかったことも想像できます。実際omabさんも2016年移行 python-social-auth にはcommitしていなくて、django-social-appもsocial-coreだけに依存しています。そこで今回の実装も social-auth-core にのみ依存するように実装しました。↩